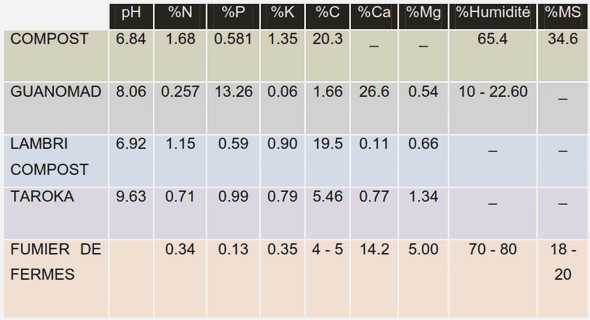
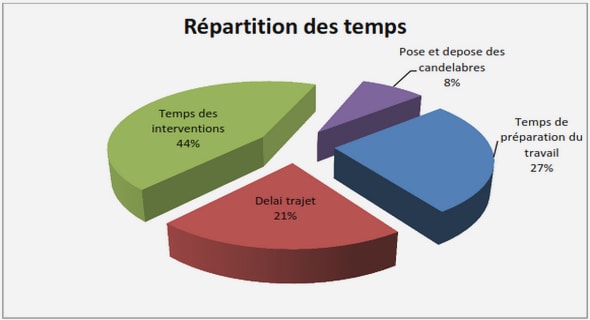
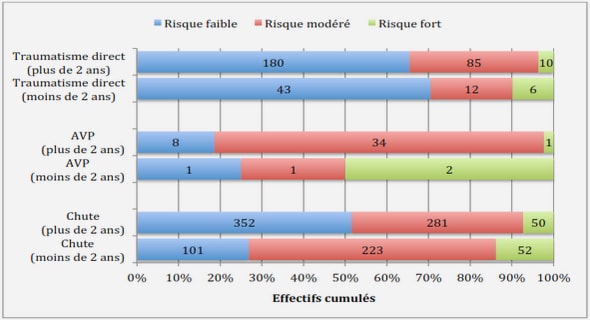
Le besoin récurrent en outils de visualisation d’information exprimé dans l’introduction trouve son origine dans l’accroissement significatif des capacités de stockage numérique. Ainsi, la quantité d’information stockée au cours de la seule année 2002 a été évaluée [LVSC03], tous formats confondus, à 5 exaoctets (5.10¹⁸ octets) et devait augmenter de plus de 30% chaque année. Concernant les données informatisées, une des conséquences de cette situation est le besoin d’interfaces adaptées permettant à l’utilisateur d’appréhender de grands volumes de données, les interfaces utilisées jusqu’à présent ne pouvant plus remplir leur fonction avec la même efficacité. Considérant le cas pratique des disques durs équipant les ordinateurs personnels, le volume de ceux-ci est passé en vingt ans de quelques mégaoctets à plusieurs centaines de gigaoctets. Les outils de gestion de fichiers ont dû s’adapter à ce changement d’échelle en proposant de nouvelles façons de représenter un système de fichiers. Ainsi, lors de son lancement en 1986, l’interface à base de listes textuelles du célèbre gestionnaire de fichiers Norton Commander était suffisante pour appréhender globalement un volume de quelques mégaoctets. L’accroissement des capacités de stockage a entraîné un accroissement du nombre de fichiers et parallèlement des hiérarchies de répertoires. De nouvelles formes de représentation sont apparues délaissant les listes textuelles. Un changement de paradigme s’est en effet opéré : le caractère visuel est le dénominateur commun de ces nouvelles représentations.
L’accroissement conjoint du volume des données et du nombre de dimensions de ces données a été qualifié par Richard Bellman de Curse of dimensionality [Bel57] (fléau de la dimension). Ainsi, l’enjeu des nouvelles formes de représentations visuelles est double. Elles doivent pouvoir gérer à la fois le volume important des données et leur nombre croissant de dimensions. Ces dimensions peuvent être de natures diverses : attributs binaires ou numériques. La structure des données peut également varier : tableaux objets/attributs, relations binaires entre objets, arbres. Les solutions visuelles doivent à la fois être adaptées à la nature des dimensions et de la structure des données, et être capable de représenter des données aux dimensions et à la structure hétérogènes. les techniques de visualisation, nous nous penchons d’abord sur la description des données. Les données manipulées ici peuvent être décrites comme un ensemble d’objets, un ensemble d’attributs (ou dimensions), des relations objet-objet, objet-attribut et attribut-attribut. Un objet correspond à un individu pour les statisticiens, un attribut est une dimension à laquelle est associé un ensemble de valeurs. Un objet o est valué sur un attribut a lorsque cet objet est associé à une valeur particulière v de l’attribut. On dit alors que l’objet o a pour valeur v sur l’attribut a. Le contexte d’accroissement et d’hétérogénéité des dimensions évoqué précédemment se caractérise donc par un grand nombre d’objets, valués sur un grand nombre d’attributs de natures différentes.
Attributs et mesures
Les attributs associés aux objets peuvent être répartis selon une typologie dépendant de la nature de leurs valeurs (ou mesures) respectives et des propriétés de celles-ci. La valeur d’un attribut peut en effet prendre la forme d’un nombre (une hauteur exprimée en mètres, le dossard d’un joueur de football, le nombre d’enfants d’une famille), d’une chaîne de caractères (un nom, une couleur, une appréciation) ou d’un caractère symbolisant les valeurs vrai ou faux. Les liens entre un attribut et ses mesures ont été étudiés par la branche théorique de la métrologie (measurement theory) [KS71, Han96]. Ces travaux sont utiles en analyse de données et en statistique descriptive dans la mesure où, pour tirer des conclusions sur un attribut, il faut prendre en compte la nature de la correspondance entre l’attribut et ses mesures [Sar95]. Stanley Smith Stevens a ainsi identifié quatre niveaux ou échelles de mesures se distinguant par les propriétés des ensembles de nombres ou de symboles constituant les mesures [Ste46].
Échelle nominale
Une échelle nominale est un ensemble non ordonné de valeurs, pouvant être considérées comme des étiquettes. Ces valeurs se présentent généralement sous forme de chaînes de caractères mais pas toujours : les numéros attribués aux joueurs d’une équipe de football constituent en effet une échelle nominale, bien que les symboles utilisés soient des entiers naturels. Les transformations basées sur l’existence d’une relation d’ordre sur N sont alors proscrites, ces entiers ne jouant, dans le cas considéré, que le rôle d’identifiants. Notons que la prise en compte de la sémantique des entités, au sens large, manipulées se révèle d’ores et déjà importante. Voir à ce sujet l’article satirique de Frederick Lord [Lor70]. Pour chacune des échelles présentées dans la suite, nous précisons leurs caractéristiques mathématiques. Pour l’échelle nominale, ce sont les suivantes :
– indicateurs de tendance centrale : mode.
– transformations possibles : permutations une à une.
– structure mathématique : ensemble non ordonné.
Échelle ordinale
Une échelle ordinale est un ensemble de valeurs muni d’un ordre total. Comme pour les échelles nominales, les valeurs sont généralement des chaînes de caractères.
– indicateurs de tendance centrale : mode, médiane.
– transformations possibles : transformations monotones croissantes.
– structure mathématique : ensemble totalement ordonné.
Échelle d’intervalles
Les valeurs d’une échelle d’intervalles sont totalement ordonnées et l’intervalle entre deux valeurs est quantifiable. Les valeurs sont nécessairement des nombres et la soustraction de deux valeurs a un sens. Notons que la différence entre les échelles ordinales et d’intervalles réside dans ce dernier point. La valeur zéro étant fixée arbitrairement, l’addition de deux valeurs n’a pas de sens.
– indicateurs de tendance centrale : mode, médiane, moyenne arithmétique, écart type.
– transformations possibles : toute transformation affine t telle que t(m) = c × m + d où c et d sont des constantes et m une valeur de l’échelle.
– structure mathématique : espace affine de dimension 1.
Échelle de rapports
La valeur zéro étant fixée de façon non arbitraire, le rapport m1/m2 entre deux valeurs a un sens, de même que l’addition, la multiplication et la division. La plupart des grandeurs physiques, telles que la masse, la longueur ou l’énergie sont mesurées sur des échelles de rapport. C’est également le cas d’une température mesurée en kelvins mais pas d’une température mesurée en degrés Celsius dont le zéro a été fixé de manière arbitraire et non selon un zéro absolu.
– indicateurs de tendance centrale : mode, médiane, moyennes arithmétique et géométrique, écart-type.
– transformations possibles : toute transformation linéaire t telle que t(m) = c × m où c est une constante et m une valeur de l’échelle.
– structure mathématique : corps.
Autres échelles
Les mesures binaires sont généralement considérées comme appartenant à une échelle nominale à deux valeurs possibles. On pourra cependant rencontrer dans la littérature les échelles de log-intervalles et absolues dont l’étude sort du cadre de ce manuscrit. En effet, le débat sur la validité des échelles de Stevens n’est pas encore clos au sein de la communauté de métrologie théorique [Lor70, Dun84, Mic86, VW93].
Des données à la visualisation
Historique et définitions
L’utilisation de métaphores visuelles pour exprimer des connaissances remonte à l’Antiquité. Pour Pythagore, arithmétique et géométrie sont sœurs : chaque point représentant une unité . En raisonnant graphiquement, les pythagoriciens ont démontré que tout entier carré est la somme de deux entiers triangles successifs. Par la suite, les premières représentations visuelles comme support pour le raisonnement ont été les diagrammes géométriques, les positions des astres et les cartes géographiques. Le développement, à partir du xvie siècle, de nouvelles techniques et instruments nécessaires à l’expansion maritime de l’Europe fut accompagné de représentations graphiques plus précises dont l’invention de l’imprimerie par Gutenberg en 1436 favorisa le déploiement. Sous l’impulsion de cette expansion territoriale, le xviie siècle est marqué par un grand renouveau des sciences en Europe (Kepler, Galilée, Newton, Descartes, Pascal, Leibniz) qui amènera à la révolution copernicienne et à l’avènement de l’héliocentrisme. Cette effervescence scientifique conduit à la mise en place de nouvelles formes de communication autres que les exposés oraux donnant lieu à d’onéreux voyages. Ainsi le premier périodique scientifique, intitulé Le Journal des savants, paraît à Paris en janvier 1665. Les premières représentations visuelles de grandeurs physiques mesurées, issues des progrès scientifiques récents, s’inscrivent dans cet effort de communication : le premier graphique statistique connu réalisé par Michael van Langren en 1644 .
Au xviiie siècle, la visualisation s’étend à des données plus abstraites issues de l’économie, de la démographique et des statistiques tandis que des innovations techniques comme la lithographie facilitent son utilisation. La première moitié du xixe siècle voit l’explosion de nouvelles formes de graphiques statistiques et l’apparition de « cartes thématiques » utilisant le support d’une carte géographique pour présenter et localiser une information d’origine le plus souvent statistique . La plupart des formes de graphiques statistiques utilisées aujourd’hui ont été introduites à cette époque, notamment les graphes en barres et les graphes circulaires par William Playfair (1759-1823).
|
Table des matières
Introduction
1 Contexte de l’étude
2 Objectifs et approche
3 Structure du mémoire
Partie I Problématique et État de l’art
Chapitre 1 Problématique
1.1 Attributs et mesures
1.2 Échelle nominale
1.3 Échelle ordinale
1.4 Échelle d’intervalles
1.5 Échelle de rapports
1.6 Autres échelles
1.7 Conclusion
Chapitre 2 Des données à la visualisation
2.1 Historique et définitions
2.2 Formalisation
2.2.1 Modèle de Card-Chi
2.2.2 Modèle de van Wijk
2.2.3 Stratégies de navigation
2.2.4 Choix effectués
2.3 Dissimilarité, distance et visualisation de proximités
2.3.1 Définitions
2.3.2 Fonctions de dissimilarité usuelles
2.3.3 Techniques de projection
2.4 Conclusion
Partie II Contributions et réalisations
Chapitre 3 Modèles formels de visualisations et expérimentations
3.1 Entités du modèle formel
3.1.1 Objets, attributs et relations
3.1.2 Atomes et liaisons
3.1.3 Forces
3.1.4 Lentilles
3.2 Modèle formel et visualisation d’une collection musicale
3.2.1 Le projet de recherche Savic
3.2.2 Mise en œuvre de la projection MDS
3.2.3 Intégration de nouveaux attributs nominaux
3.2.4 Bilan
3.3 Modèle formel et visualisation d’une base documentaire scientifique
3.3.1 Le projet de recherche ToxNuc-E
3.3.2 Représentation explicite d’une structure de type graphe
3.3.3 Bilan
3.4 Synthèse des verrous identifiés
3.4.1 MDS sélective et données manquantes
3.4.2 Attributs hétérogènes
3.4.3 Hétérogénéité de la structure
3.4.4 Volume des données
3.5 Conclusion
Chapitre 4 Analyse de concepts formels
4.1 Approche intuitive
4.1.1 Concepts, extensions, intensions et treillis de concepts
4.1.2 Représentation graphique, extensions et intensions réduites
4.2 Approche formelle, définitions et notations
4.3 Contextes multivalués et échelles conceptuelles
4.4 Variantes
4.4.1 Treillis iceberg
4.4.2 Sous-hiérarchie de Galois
4.5 Outils
4.6 Applications en recherche d’information
4.7 Conclusion
Chapitre 5 Projection MDS sélective de données creuses assistée par FCA
5.1 Identification des couples
5.2 Organisation visuelle : principe général
5.2.1 Conteneurs
5.2.2 Mise en œuvre dans Molage
5.3 Organisation visuelle : détails sur CO
5.4 Organisation visuelle : détails sur CA
5.4.1 Reconstitution du diagramme de Hasse
5.4.2 Distances euclidienne et de Jaccard
5.5 Conclusion
Chapitre 6 Navigation visuelle overview + detail dans un contexte mixte
6.1 Diagrammes enchevêtrés (nested-line diagrams)
6.2 La projection MDS comme alternative aux diagrammes enchevêtrés
6.2.1 Échelles nominale et dichotomique
6.2.2 Échelles ordinale et biordinale
6.3 Interactions visuelles entre attributs non binaires
6.3.1 Attributs du premier facteur et vue globale
6.3.2 Attributs du second facteur et vue locale
6.4 Corrélations entre attributs numériques
6.5 Projection MDS du premier facteur
6.6 Conclusion
Chapitre 7 Sélection d’attributs
7.1 Sélection d’attributs : principes fondamentaux
7.2 Prétraitements et attribut de classe
7.3 Proposition
7.3.1 Génération des sous-ensembles candidats
7.3.2 Évaluation des sous-ensembles candidats
7.4 Exemple
7.5 Interprétation et implications
7.6 Conclusion
Conclusion