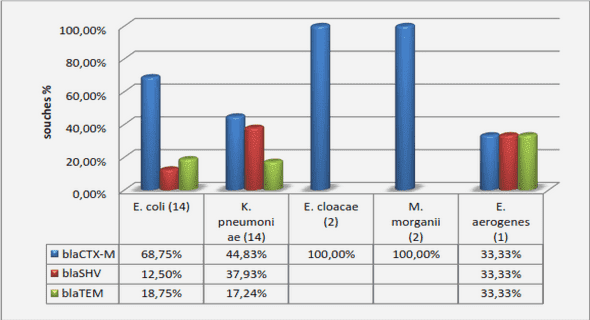
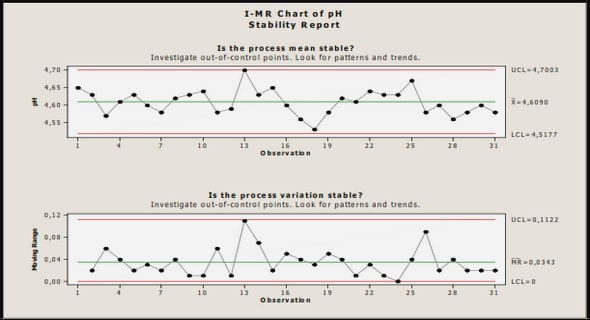
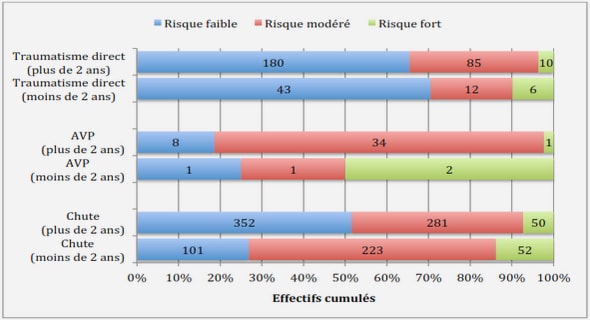
L’apprentissage automatique (Machine learning) est une discipline vouée à mettre en place des théories et des algorithmes permettant à une machine d’apprendre automatiquement des règles d’analyse et de décision. Ces règles automatiques couvrent les besoins en traitement des données tels que la représentation, l’extraction d’information et la reconnaissance automatique. De manière moins formelle, l’apprentissage automatique consiste à transférer un défaut de connaissance a priori de l’expert vers une machine (un ordinateur). Celle-ci, plus à même qu’un Homme d’explorer un vaste ensemble d’hypothèses, doit alors construire, par elle-même, un outil répondant au besoin de l’expert. En ce sens, l’apprentissage automatique répond à l’impossibilité de modéliser un phénomène pour en distiller l’information utile. L’ordinateur, de concert avec les algorithmes et les théories d’apprentissage automatique, se présente comme un moyen alternatif d’arriver au but recherché, en remplaçant la capacité d’abstraction et de réflexion de l’Homme par l’exploration systématique d’un espace d’hypothèses.
ÉLÉMENTS D’APPRENTISSAGE STATISTIQUE
L’apprentissage statistique est une discipline des mathématiques appliquées à la frontière de quatre domaines : les statistiques, l’analyse fonctionnelle, l’optimisation et l’informatique. Elle regroupe un ensemble de méthodes visant à modéliser un phénomène physique à partir d’observations de celui-ci et des moyens calculatoires actuels, de la manière la plus directe possible. Les statistiques incarnent le fondement de cette discipline, par le cadre théorique qu’elles fournissent, permettant ainsi de généraliser des propriétés inférées des observations antérieures à toute observation inédite. Les modèles utilisés pour décrire le phénomène physique d’intérêt tiennent leurs origines de l’analyse fonctionnelle et sont souvent (mais pas nécessairement) déterminés par la résolution d’un problème d’optimisation (i.e. un problème consistant à déterminer les minima d’une fonction d’énergie, plus couramment appelée fonction de coût), mettant en jeu tout un panel d’algorithmes et bien entendu, des systèmes informatiques adéquats. Il est un principe important en apprentissage statistique (que l’on peut résumer par utiliser la manière la plus directe) : il est sage d’éviter toute étape intermédiaire entre les données et le but à atteindre (la modélisation du phénomène) car il y a fort à parier que les marches intermédiaires soient individuellement plus difficiles à franchir que le but recherché lui-même. Ainsi, l’apprentissage statistique se place de facto en opposition aux approches bayésiennes qui cherchent systématiquement à capturer le mécanisme de génération des observations, peu importe le but recherché. En pratique, il est souvent plus difficile d’accéder à une telle information qu’à une représentation du phénomène d’intérêt.
Formalisme
Les observations que nous avons mentionnées auparavant sont des vecteurs caractéristiques x, regroupant des descripteurs appelés variables explicatives. Il est alors d’usage de distinguer deux branches de l’apprentissage statistique : l’apprentissage supervisé et nonsupervisé. Dans ce dernier, les observations sont au centre des débats et l’on va, par exemple, chercher à mettre en place des techniques de séparation aveugle (Analyse en Composantes Principales (ACP), analyse en composantes indépendantes, factorisation de matrices, etc.) et de création automatique de groupes (clustering). En apprentissage supervisé, chaque observation x est accompagnée d’une étiquette y (elle aussi observée), aussi appelée variable expliquée. De manière plus rigoureuse, une observation est un couple (x, y) dont la première partie sert à expliquer la deuxième. La finalité de l’apprentissage supervisé est, à partir d’observations étiquetées, d’inférer une règle f donnant l’étiquette y associée à une observation inédite x ; autrement dit, d’établir un lien de cause à effet entre les deux entitées : y = f(x).
Suivant la nature de l’étiquette y, on distingue trois familles d’approches :
❖ la régression : les étiquettes sont prises dans R ;
❖ la classification multi-classe : les étiquettes proviennent de J1, KK (K étant un entier au moins égale à 3) ;
❖ la classification binaire : les étiquettes sont dans {−1, 1}, abrégé {±1}. Il est équivalent de concevoir les étiquettes dans {1, 2} mais la notation précédente simplifie les expressions mathématiques.
Pour la suite de ce manuscrit (et conformément à nos travaux), nous nous placerons dans le cadre de l’apprentissage supervisé et nous nous concentrerons sur des problèmes de classification binaire. Une grande partie de ce qui est écrit dans cet chapitre (concernant l’apprentissage automatique) peut être naturellement étendue à la régression et (de manière moins évidente) à la classification multi-classe. En revanche, nous ne traiterons aucunement d’apprentissage statistique non-supervisé.
Interprétation géométrique
Jusqu’ici, nous avons présenté les SVM comme des outils d’apprentissage statistique possédant une particularité fonctionnelle (l’utilisation d’un RKHS comme espace des hypothèses) qui, par la suite, se sont ouverts à plusieurs variantes à travers le choix des fonctions de régularisation et de perte. Ce serait un tort de négliger l’interprétation géométrique d’une SVM, qui donne une intuition de la notion de régularisation, différente de celle consistant à limiter les variations de f.
Pour ce faire, nous introduisons à présent le concept d’espace de redescription, qui représente un nouvel espace de Hilbert, potentiellement de grande dimension, dans lequel les données sont réarrangées et traitées comme deux classes linéairement séparables. Le théorème suivant, dû à Aronszajn, nous affirme l’existence d’un tel espace et d’une fonction de redescription permettant de lier les entrées à leurs images dans ledit espace.
|
Table des matières
Introduction
Motivations
Contributions
Organisation du manuscrit
Publications
1 Apprentissage automatique
1.1 Introduction
1.2 Éléments d’apprentissage statistique
1.2.1 Formalisme
1.2.2 Approche bayésienne
1.2.3 Approche fréquentiste
1.2.4 Optimisation et convexité
1.3 Machine à vecteurs supports
1.3.1 Définition fonctionnelle
1.3.2 Approche numérique
1.3.3 Interprétation géométrique
1.4 Sélection de modèle
1.4.1 Risque structurel
1.4.2 Critères
1.4.3 Apprentissage de noyau multiple
1.4.4 Apprentissage de noyau multiple genéralisé
1.5 Apprentissage d’instance multiple
1.5.1 Définition
1.5.2 Algorithmes
1.6 Synthèse
2 Reconnaissance de signaux
2.1 Introduction
2.2 Descripteurs
2.3 Agrégation
2.4 Transformées temps-caractéristique
2.4.1 Distribution bilinéaire
2.4.2 Banc de filtres
2.4.3 Réseau neuronal
2.4.4 Transformée en ondelettes
2.4.5 Diffusion d’ondelettes
2.4.6 Dictionnaire
2.5 Reconnaissance précoce
2.5.1 Motivations
2.5.2 Classification
2.5.3 Détection
2.6 Synthèse
3 Apprentissage d’une représentation TF convolutive
3.1 Introduction
3.2 Formalisation du problème
3.3 Approche directe
3.3.1 Cas d’école
3.3.2 Cas général
3.3.3 Comparaison numérique
3.4 Régularisation par famille génératrice
3.4.1 Restriction du problème
3.4.2 Apprentissage de la transformée temps-fréquence
3.4.3 Conditions d’équilibre
3.4.4 Détails d’implémentation
3.4.5 Détermination automatique de la fonction d’agrégation
3.4.6 Relation avec l’état de l’art
3.5 Expériences numériques
3.5.1 Paramétrisation des méthodes
3.5.2 Données synthétiques
3.5.3 Problème d’interface cerveau-machine
3.5.4 Scènes acoustiques
3.6 Synthèse
4 Un modèle de détecteur précoce
4.1 Introduction
4.2 Détection précoce
4.2.1 Espace de similarité
4.2.2 Modèle pour la détection précoce
4.2.3 Une représentation par similarités adéquate
4.3 Algorithme d’apprentissage et analyse de complexité
4.3.1 Problème d’apprentissage
4.3.2 Algorithme par ensemble actif
4.3.3 Algorithme incrémental
4.3.4 Complexité du modèle
4.4 Discussion
4.5 Expériences numériques
4.5.1 Comparaison des approches de résolution
4.5.2 Fiabilité
4.5.3 Précocité
4.5.4 Fonctionnement en temps réel
4.6 Synthèse
Conclusion