Notions théoriques
REST n’est pas un protocole, c’est un style d’architecture utilisé pour la conception de services Web. Il a été introduit en 2000 par Roy Fiedling dans sa thèse de doctorat. Cette méthodologie est une alternative au protocole SOAP. REST fournit un ensemble de contraintes architecturales qui permettent d’accéder et de manipuler les données. L’adjectif anglais « RESTful » qualifie les systèmes qui respectent les contraintes architecturales de REST. Utilisé par les colosses de l’informatique (Google, Amazon, …), REST se base uniquement sur le protocole HTTP pour la communication client-serveur. Les développeurs peuvent faire une lecture avec POST, faire une suppression avec GET ou bien faire une mise à jour avec DELETE. Mais l’application ne respecte plus les exigences REST et n’est plus « RESTful ». En effet, il est très coutumier de voir des développeurs utiliser la méthode GET pour lire, insérer et supprimer un élément alors que cette méthode est censée être utilisée uniquement pour la lecture d’information.
Une méthode est dite « safe » quand elle ne change pas l’état d’une ressource (GET). Une méthode est « idempotente » quand les traitements appliqués à plusieurs reprises produisent le même résultat. En d’autres termes, faire de multiples demandes identiques a le même effet que de faire une demande unique (GET, PUT, DELETE et PATCH). Il est important de noter que la réponse à une requête n’est pas une ressource c’est la représentation de la ressource que le client reçoit. En effet, une ressource peut avoir plusieurs représentations (XML, JSON, HTML et TEXT). Quand le client demande une ressource, il doit définir le format de réponse (représentation) qu’il souhaite. REST propose des services sans états (statelessness). Le serveur ne connaît aucun élément sur le client, il ne gère pas les sessions. Chaque requête est traitée de manière indépendante ce qui veut dire que la requête envoyée au serveur doit contenir toutes les informations relatives à son état. L’exemple ci-dessous illustre parfaitement le concept « statelessness » : Figure 13 : Exemple statelessness
Dans cet exemple, la première activité permet de rechercher les dix premiers résultats avec le mot clé « Genève ». Le service ne conservant pas l’état (recherche des dix premiers résultats), la recherche des dix résultats suivants nécessite d’ajouter un paramètre (ici start=10). Cependant, un des principes intéressants de REST est qu’il fournit en plus du résultat de la demande, des liens hypermédia permettant d’accéder à d’autres fonctions ou d’autres ressources disponibles sur le serveur (HATEOAS). Par exemple, si un appel vers le serveur demande la liste des cinq premiers étudiants alors ce dernier retourne non seulement la liste des cinq premiers étudiants, mais envoie également un lien permettant d’aller consulter les cinq prochains étudiants ou d’autres fonctions notamment la suppression ou la modification. En résumé, REST propose des contraintes architecturales qui permettent à un client et un serveur d’échanger des données par le biais du protocole HTTP. REST n’est pas un protocole ni une technologie à part entière, il s’agit d’un ensemble de principes et bonnes pratiques.
Principes de base de REST
Une bonne construction des URI est primordiale lors de la conception d’un service Web REST. Les liens (URI) dérivent de la hiérarchie des ressources et sont pour cette raison construits du plus général au plus particulier. Prenons l’exemple d’une ressource composée d’une collection d’éléments (nommé « element ») dont chaque élément est lui-même associé avec une autre collection. Cette dernière collection contient des éléments nommés « sous-element ». Les principes REST exigent que la première collection soit appelée « elements » et que chaque membre de la collection soit nommé « element ». La syntaxe du lien permettant l’accès à l’élément de la première collection dont l’identifiant est « r » est « elements/r ». De même, la syntaxe pour l’accès à l’élément de la seconde collection dont l’identifiant est « sr » pour l’élément « r » est « elements/r/sous-elements/sr ». Le diagramme d’activité ci-dessous explique la manière dont les URI doivent être construites à partir d’une collection d’étudiants (première collection) inscrits à une collection de cours (deuxième collection). L’URI « GET :http://serveur.com/application/etudiants » permet de récupérer la collection des étudiants. Une erreur de conception (qui n’empêche pas le service Web de fonctionner) serait d’utiliser le nom de l’objet au singulier pour récupérer une collection « GET :http://monserveur.com/application/etudiant ».
En ajoutant un paramètre à l’URI (r = le numéro de l’étudiant), l’utilisateur du service peut récupérer un étudiant spécifique « GET :http://serveur.com/application/etudiants/1 ». Le reste de la construction doit garder la même structure hiérarchique (du plus général au plus particulier). Dans ce cadre, la collection des cours de l’étudiant numéro 1 est récupérée de la manière suivante « GET :http://serveur.com/application/etudiants/1/cours ». La note d’un cours (ici programmation) est retournée quant à elle avec l’URI « GET :http://serveur.com/application/etudiants/1/cours/programmation ». Le tableau suivant montre l’utilisation des méthodes HTTP (GET, POST, PUT, DELETE) pour accéder à des collections ou des éléments. Les principales fonctions du tableau ci-dessus sont illustrées par un exemple basé sur la collection d’étudiants utilisée précédemment. 3.4.3.2.1 Lire une collection Pour lire une collection, l’utilisateur doit utiliser la méthode «GET» avec l’URI « GET:http://serveur.com/application/etudiants ».
OAuth est un standard ouvert pour l’autorisation et non un protocole d’authentification. La première version (OAuth1.0a) est standardisée depuis avril 2010 et sa version actuelle (OAuth2.0) est disponible depuis octobre 2012. Cette dernière version corrige des problèmes de sécurité, mais simplifie également l’interopérabilité entre les différentes applications. Dans ce cadre, OAuth permet à une application d’utiliser l’API sécurisée d’un autre fournisseur pour authentifier un utilisateur. A cet effet, l’application implémente le service OAuth mis à disposition par le fournisseur. L’authentification est alors gérée par le fournisseur qui retourne à l’application l’autorisation ou le refus de connexion et éventuellement d’autres informations. Le principal avantage d’utiliser ce standard est que l’utilisateur n’est pas obligé de créer un compte spécifique pour l’application fournissant le service. Les sites Internet et les applications mobiles proposent de plus en plus à un utilisateur de se connecter à partir de son compte Twitter, Facebook ou encore Google. Cette fonctionnalité a l’avantage de faciliter les connexions de l’utilisateur à l’application, mais a pour désavantage de potentiellement fournir des informations relatives à votre compte. Par exemple, l’API OAuth de Google retourne non seulement l’autorisation de connexion, mais également des informations sur profil de l’utilisateur telles que le nom complet ou l’adresse email. Il est évident que l’utilisateur doit faire confiance à l’application faisant appel au service OAuth d’un fournisseur tiers avant une éventuelle connexion. Côté développement beaucoup de bibliothèques ont été conçues dans les langages de programmation les plus utilisés pour permettre d’implémenter cette technologie dans les nouvelles applications. OAuth est caractérisé par quatre rôles distincts :
Architecture et schéma réseau
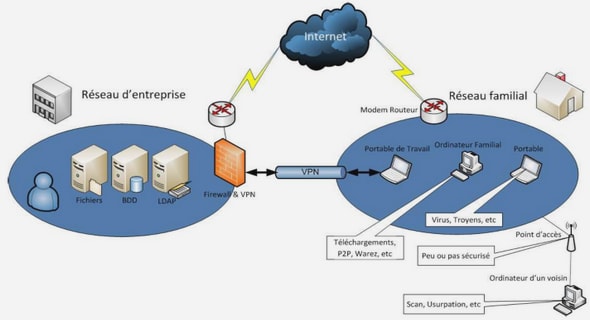
L’architecture de la solution doit permettre d’accéder depuis l’extérieur (Internet) à des informations stockées dans la base de données interne du CSCQ via un service Web. Une communication de l’extérieur vers le CSCQ n’était pas possible avant ce projet, car les HUG bloquaient les échanges pour des raisons de sécurité du réseau hospitalier. Comme expliqué au début du document, le CSCQ dispose d’une configuration réseau particulière, car l’entreprise est logée dans les locaux des HUG et utilise le réseau informatique de l’hôpital. Par mesure de confidentialité, le serveur contenant la base donnée interne du CSCQ est nommé « S1 » et la nouvelle machine (nécessaire pour la solution retenue) est nommée « S2». Cette dernière dispose d’un serveur « Apache Tomcat » qui gère le service Web du CSCQ. Pour mener à bien ce projet, plusieurs solutions ont été étudiées en interne (CSCQ) et proposées par la suite aux responsables réseau des HUG. Plusieurs échanges entre les deux parties ont permis de définir une solution satisfaisant à la fois les contraintes du CSCQ et des HUG. La configuration retenue est décrite sur la figure suivante.
La machine « S2 » est intégrée dans le réseau du CSCQ, mais elle est rendue accessible par Internet. Les accès depuis l’extérieur (Internet) sont filtrés par un premier pare-feu puis traversent un « reverse proxy ». Comme son nom l’indique, un « reverse proxy » est le miroir d’un « proxy ». Un « proxy » permet à un utilisateur d’un réseau interne d’accéder à Internet tandis qu’un « reverse proxy » permet à un utilisateur Internet d’accéder à un réseau interne. Les accès traversent ensuite un second pare-feu puis accèdent à la machine « S2 ». Pour plus de sécurité, une restriction a été imposée, la machine « S2 » n’est accessible depuis Internet que par le port du serveur « Apache Tomcat ». De plus, les HUG proposent un certificat SSL/TLS, ce qui permet d’utiliser le protocole HTTPS sur la machine « S2 » et donc d’avoir une communication cryptée avec le client. La prochaine figure permet de mieux comprendre les interactions entre le client et le service Web hébergé sur le serveur « Apache Tomcat » de la machine « S2 ». Cette figure est simplifiée afin de faciliter sa compréhension.
|
Table des matières
Déclaration
Remerciements
Résumé
Liste des tableaux
Liste des figures
1. Glossaire
2. .Introduction
2.1 Avant-propos
2.2 Objectif du travail
2.3 Problématique du sujet
2.3.1 Environnement
2.3.2 Sécurité
2.4 Aspects théoriques et mise en pratique
3. Recherche théorique
3.1 Qu’est-ce qu’un service Web ?
3.1.1 Définition
3.1.2 Fonctionnement et démarche côté client
3.1.3 Fonctionnement et démarche côté serveur
3.2 Pourquoi les services Web ?
3.3 Les précurseurs des services Web
3.3.1 CORBA
3.3.1.1 Historique et principes
3.3.1.2 Avantages
3.3.1.3 Inconvénients
3.3.2 DCOM
3.3.2.1 Historique et principes
3.3.2.2 Avantages
3.3.2.3 Inconvénients
3.3.3 RMI
3.3.3.1 Historique et principes
3.3.3.2 Avantages
3.3.3.3 Inconvénients
3.3.4 Comparaison
3.4 Les architectures actuelles
3.4.1.1 Notions de base des protocoles de communication sur le Web
3.4.2 500 à 505. Cette classe représente les erreurs du serveur.
3.4.3 REST
3.4.3.1 Notions théoriques
3.4.3.2 Principes de base de REST
3.4.3.2.1 Lire une collection
3.4.3.2.2 Modifier une collection
3.4.3.2.3 Supprimer une collection
3.4.3.2.4 Lire un élément d’une collection
3.4.3.2.5 Ajouter un élément à une collection
3.4.3.2.6 Modifier un élément d’une collection
3.4.3.2.7 Supprimer un élément d’une collection
3.4.4 SOAP
3.4.4.1 Notions théoriques
3.4.4.1.1 Découverte et publication de services
3.4.4.1.2 Description de services
3.4.4.1.3 Communication
3.4.4.1.4 Transport
3.4.4.2 Principes de base de SOAP
3.4.5 Comparaison
3.5 Sécurité des services Web
3.5.1 Sécurité côté réseau et hardware
3.5.2 Sécurité en REST
3.5.2.1 Authentification basique HTTP
3.5.2.2 OAuth
3.5.3 Sécurité en SOAP
3.5.3.1 WS-Security
3.6 Format de sortie de données
3.6.1 HTML
3.6.2 XML
3.6.3 JSON
3.6.4 Comparaison
4. Pratique
4.1 Architecture et schéma réseau
4.2 Tomcat
4.3 Accès aux informations (Base de données)
4.3.1 Tables
4.3.2 Procédures stockées
4.4 Service Web
4.4.1 Développement de l’application
4.4.2 Services
4.4.2.1 Ouverture d’une session (login)
4.4.2.2 Fermeture d’une session (logout
4.4.2.3 Lecture du groupe d’expédition
4.4.2.4 Lecture des informations administratives
4.4.2.5 Lecture des programmes
4.4.2.6 Lecture des paramètres d’un programme
4.5 Environnement de test
4.6 Application Android
4.6.1 Avant-propos
4.6.2 Développement de l’application
4.6.2.1 Activité authentification (login
4.6.2.2 Activité groupe d’expédition
4.6.2.3 Activité menu
4.6.2.4 Activité informations administratives
4.6.2.5 Activité programmes
4.6.2.6 Activité paramètres
4.6.2.7 Activité « Contactez le CSCQ »
4.6.2.8 Traitement des messages d’erreurs
4.6.2.8.1 Erreur 503
4.6.2.8.3 Erreur 440
4.6.2.8.2 Erreur 401
4.6.2.8.4 Erreur 429
5. Conclusion
6. Expérience personnelle
Bibliographie
Annexe 1 : Table ASCII
Annexe 2 : Tableau alphabet Base64
Annexe 3 : Extrait de la table « T1 »
Annexe 4 : Extrait de la table « T2 »
Annexe 5 : Extrait de la table « T3 »
![]() Télécharger le rapport complet
Télécharger le rapport complet