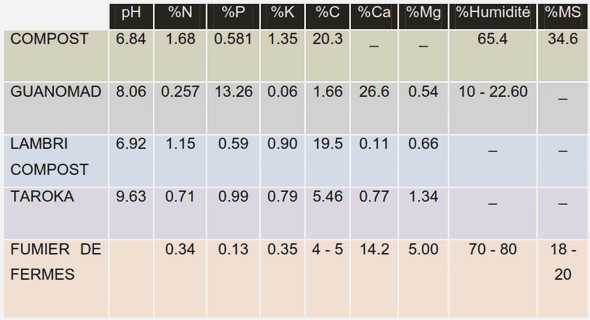
Les propriétés des indices d’inégalité
Avant de décomposer les indices d’inégalité, il semble opportun d’étudier l’objet en question. Ainsi, cette partie s’attache à présenter les principaux indices d’inégalité utilisés dans la littérature. Cette synthèse s’inspire notamment de l’ouvrage de Villar (2017).
Un indice d’homogénéité linéaire n’est pas adapté pour étudier les inégalités de revenus puisqu’il induit qu’une société à deux individus, où l’un a un revenu de 100€ et l’autre de 1000€, est aussi inégalitaire que s’ils avaient respectivement 100 100€ et et 101 000€, alors que dans la différence de richesse est beaucoup plus faible dans le second cas. Un indice d’homogénéité de degré 1 peut avoir un intérêt lorsque que le « volume des inégalités » est pris en considération, c’est-à dire pour faire une différence entre une situation où un individu gagne 100€ et l’autre 1 000€ d’une situation où l’un gagne 1 000€ et l’autre 10 000€. Dans les deux cas de l’exemple précédent, le second individu a un revenu 10 fois plus important que le premier, l’indice relatif estimera donc que les deux situations de cette société à deux individus est similaire d’un point de vu inégalitaire. L’avantage considérable d’un indice relatif est qu’il permet directement de comparer différentes sociétés dans le temps ou à un temps donné, puisqu’il n’est pas sensible aux différents échelles monétaires entre ces sociétés. Un indice d’homogénéité de degré 1 peut aussi le faire, mais après avoir transformé les revenus de telle sorte qu’ils soient comparables dans le temps ou entre différentes sociétés à un temps donné. Cependant, dans ce dernier cas, l’indice sera sensible à l’année de base choisie pour comparer des revenus dans le temps.
Un autre principe a été mis en avant par Cowell et Flachaire (2018), celui de la monotonie à la distance.
— Monotonie à la distance :
Un indice d’inégalité respecte le principe de monotonie à la distance si l’inégalité mesurée augmente après que le revenu d’un individu s’écarte du point de référence (i.e. moyenne, médiane…), toutes choses égales par ailleurs. Formellement, avec deux distributions ya, yb ∈ D+ identiques à l’exception d’une variation du revenu d’un individu i tel que |yai − y¯a| < |ybi − y¯b|, où ¯ya et ¯yb représentent le point de référence respectif à chaque distribution, alors I(ya) < I(yb).
Comme l’ont mis en avant Cowell et Flachaire (2018), la majorité des indices d’inégalité utilisés dans la littérature sont construits tel qu’au numérateur se trouve un indice de dispersion et au dénominateur la moyenne. Cette construction ne permet pas d’assurer le principe de monotonie à la distance car si un riche (par rapport à la moyenne) devient plus riche alors le numérateur et le dénominateur augmente, ce qui peut potentiellement conduire à une baisse de l’indice d’inégalité.
Ce principe est très intéressant dès lors que l’évolution des inégalités dans le temps est étudiée puisqu’un indice d’inégalité qui ne respecte pas ce principe pourrait donner une image faussée de l’évolution des inégalités . Par exemple, dans le cas d’un indice basé sur la moyenne, si la classe moyenne riche a un revenu plus important alors le revenu moyen augmente et la classe moyenne pauvre devient plus pauvre et contient potentiellement plus d’individus, il parait donc justifié de dire que les inégalités augmentent, cependant un indice qui ne respecte pas l’axiome de monotonie à la distance peut conduire à la conclusion inverse. Avant de présenter les principaux indices d’inégalité réguliers utilisés dans la littérature, nous allons discuter de la variance, un indice de dispersion qui ne peut être assimilé à un indice d’inégalité. La différence entre les deux réside dans le fait qu’un indice d’inégalité fait la différence entre une dispersion de revenu qui a lieu dans le haut de la distribution par rapport à une dispersion qui a lieu dans le bas de la distribution.
La courbe de Lorenz et l’indice de Gini
La courbe de Lorenz
Les indices d’inégalité sont des indices de concentration des richesses, c’est-à-dire qu’ils sont basés sur la comparaison entre la part des richesses détenues par les individus et la part qu’ils représentent dans la société. Cette idée est représentée graphiquement par la courbe de Lorenz (1905) . Pour construire ces graphiques, la distribution des revenus y des individus est classée par ordre croissant : y1 ≤ y2 ≤ … ≤ yn. La part cumulée de la population des plus pauvres aux plus riches est représentée en abscisse et la part cumulée des richesses est représentée en ordonnée. Ainsi, la bissectrice de l’angle de l’origine de ces graphiques représente le cas parfaitement égalitaire, où la part des richesses détenues par des individus est égale à la part de ces individus dans la population totale. La différence entre la diagonale et chaque courbe représentant la concentration des richesses du cas étudié nous donne une mesure des inégalités.
Graphiquement, à l’aide du critère de la dominance de Lorenz, les deux distributions sont comparables si leur courbe ne se croisent pas , celle du dessus représentant une distribution relativement plus égalitaire. De plus, il est intéressant de noter que quand une courbe domine une autre en tout points, tous les indices synthétiques donneront une valeur moins importante pour la première que pour la seconde. Ce qui n’est pas vérifié quand les courbes se croisent (Dasgupta et al. (1973), Rothschild et Stiglitz (1973)). Lorsqu’elles se croisent , il est difficile de dire qu’elle est la situation la plus inégalitaire, cela conduit à utiliser des indices synthétiques basés sur cette courbe pour pouvoir comparer les distributions correspondantes. L’un des indices synthétiques les plus populaires, basé sur la courbe de Lorenz, est l’indice de Gini.
Les indices d’Atkinson
Une approche normative
Les indices d’Atkinson font partis des indices d’inégalité normatifs, c’est-à-dire qu’ils modélisent explicitement les inégalités comme une perte de bien-être social. Les indices d’inégalité étudiés précédemment reposent eux aussi sur des jugements, mais de manière implicite, notamment par le choix de la sensibilité d’un indicateur aux moins biens lotis. Deux approches normatives sont différenciées, d’une part celle qui évalue les inégalités par une fonction de bien-être social à la Arrow, c’est-à-dire en agrégeant les utilités individuelles en un indicateur de bien être social. D’autre part, l’approche qui évalue une distribution de revenus sans passer par les utilités individuelles. Les indices d’Atkinson font partie des indices d’inégalité basés sur des fonctions de bien-être social à la Arrow. Dans le contexte des inégalités, les alternatives sociales offertes aux individus sont limitées aux différentes redistributions de revenus. Communément, la fonction de bien-être social dépend de la taille du revenu total, souvent représentée par la moyenne, et de la distribution du revenu, représentée par un indice d’inégalité. Pour que cette fonction soit décroissante par rapport au niveau des inégalités, il est supposé qu’elle est strictement quasi-concave. De cette manière, quand tous les individus ont la même fonction d’utilité qui dépend uniquement de leur revenu, et qui est strictement concave, un transfert de revenu d’un riche à un pauvre améliore le bien-être social puisque la baisse d’utilité du riche est plus que compensée par une hausse d’utilité du pauvre (i.e. le principe de transfert de Dalton est donc respecté). La concavité de la fonction d’utilité des agents est un principe essentiel qui conduit à ce que la situation d’égalité parfaite soit celle qui maximise le bienêtre social. Cependant, une fonction d’utilité sociale en forme de U inversé est possible, où l’utilité maximale serait obtenue pour un certain niveau d’inégalité. Ceci peut s’expliquer par exemple par le fait que les individus préfèrent vivre dans une société méritocratique où le revenu est basé sur le mérite, et préféreraient donc avoir un certain niveau d’inégalité dans la société dans la mesure où les différences de revenu sont issues de différences dans le mérite pour l’obtenir.
|
Table des matières
Introduction générale
1 Les indices d’inégalité
1.1 Les propriétés des indices d’inégalité
1.2 La variance
1.3 La courbe de Lorenz et l’indice de Gini
1.3.1 La courbe de Lorenz
1.3.2 L’indice de Gini
1.4 Les indices d’inégalité de Theil
1.4.1 L’indice de Theil
1.4.2 L’indice second de Theil
1.4.3 Les indices généralisés de Theil
1.5 Les indices d’Atkinson
1.5.1 Une approche normative
1.5.2 Les indices d’Atkinson
1.6 Fonction d’Évaluation Sociale
1.7 Discussion et conclusion
2 Les décompositions des indices d’inégalité
2.1 Introduction
2.2 La décomposition par sous-populations
2.2.1 Décomposition agrégative, additive et cohérente
2.2.2 Décomposition additive et cohérente des indices d’entropie
2.2.3 Décomposition additive de l’indice de Gini
2.2.4 La décomposition faible des α − Gini
2.3 La décomposition par facteurs
2.3.1 Décomposition d’un indice d’inégalité par facteurs
2.3.2 La décomposition par facteurs de l’indice de Gini
2.3.3 La décomposition tridimensionnelle de la variation de l’indice de Gini
2.4 La décomposition multiple basée sur des méthodes statistiques : les régressions RIF
2.4.1 Effet de composition et effet structurel
2.4.2 Les régressions RIF
2.5 La décomposition de Shapley des indices d’inégalité
2.5.1 Introduction au concept de Shapley
2.5.2 Décomposition d’un modèle hiérarchique
2.5.3 Normalisation des distributions de facteurs équivalents
2.5.4 Incidence de l’indice d’inégalité sur la décomposition
2.6 Discussion et conclusion
3 L’importance du genre à l’inégalité salariale dans la fonction publique : une analyse régionale
3.1 Introduction
3.2 Mesure de l’intensité des inégalités liées au genre dans la fonction publique, des disparités importantes entre les régions
3.2.1 Méthodologie et données
3.2.2 Comparaison interrégionale de l’intensité des inégalités liées au genre sur l’ensemble de la fonction publique
3.3 Quel lien avec les spécificités régionales ?
3.3.1 Spécificités dans la structure de la fonction publique
3.3.2 Un parallèle avec des caractéristiques socio-démographiques et le secteur privé
3.4 Intensité régionale des inégalités liées au genre par catégorie et par versant
3.5 Discussion et conclusion
3.6 Annexes
4 Contribution marginale pure, interactions et l’importance d’un attribut
4.1 Introduction
4.2 Jeu inégalitaire
4.3 L’importance d’un attribut
4.3.1 Contribution marginale
4.3.2 Les interactions entre les attributs
4.4 Discussion et conclusion
4.5 Annexe
5 Mesurer l’impact d’une politique égalisatrice sur l’inégalité : une application à l’écart de rémunération entre les femmes et les hommes en France
5.1 Introduction
5.2 Les attributs, leur importance et leur impact
5.2.1 Les distributions associées aux attributs
5.2.2 L’importance de l’attribut genre
5.2.3 L’impact d’une politique égalisatrice efficace
5.3 L’impact de la surpression de l’écart de salaire entre les hommes et les femmes, une application sur données françaises
5.3.1 Les données
5.3.2 L’importance de l’attribut genre
5.3.3 L’impact du genre
5.3.4 L’interprétation des interactions
5.3.5 Un effet de composition sur l’importance du genre
5.4 Discussion et conclusion
5.5 Annexe : Distribution des observations
Conclusion générale
Bibliographie