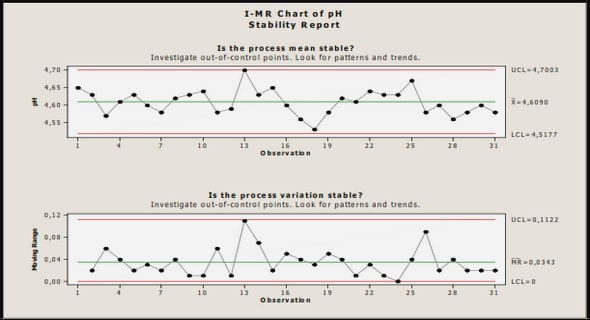
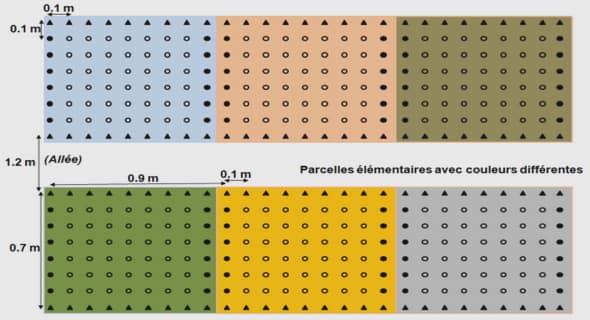
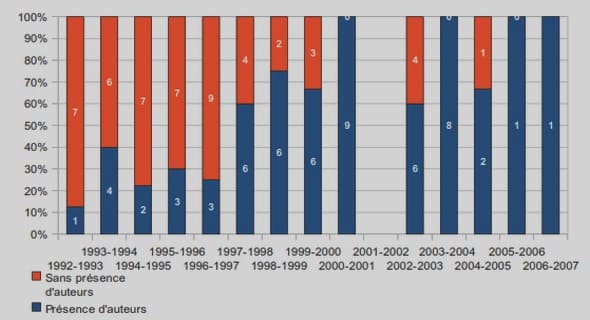
Régression linéaire multiple
La première méthode a avoir été utilisée en régionalisation fut la régression linéaire multiple. Pour cette technique, un modele de regression lineaire est construit a partir de descripteurs physiques (superficie, pente, elevation, couverture au sol, etc.) des bassins versants jauges ou le modele hydrologique a ete prealablement cale. Les descripteurs servent de predicteurs pour le modele de regression, alors que la valeur du parametre est la valeur a predire. Il est alors possible d’estimer la valeur du parametre au site non-jauge en se basant sur les caracteristiques de ce dernier, tel qu’illustre a la Figure 2.1. Wagener et Wheater (2006) ont exprime la methode selon la formulation suivante : L represente la valeur estimee du parametre au bassin non-jauge, HR est le modele de regression liant les parametres cales du modele hydrologique sur les bassins jauges R aux descripteurs des bassins jauges _ɸ_ et vR represente l’erreur residuelle du modele de regression. Le processus est repete pour chacun des parametres, generant ainsi un jeu de parametres complet a utiliser sur le site non-jauge. Cette methode a l’avantage d’etre simple a mettre en oeuvre, mais elle fait l’hypothese que les parametres ne sont pas correles entre eux et qu’ils sont des fonctions des descripteurs physiques. Effectivement, les parametres sont estimes de maniere independante. Cette methode ne tient donc pas compte de l’interaction parametrique qui est attendue dans un modele hydrologique de grande dimensionnalite, soit qui contient plusieurs parametres correles. Parajka et al. (2013) ont montre que la methode de regression lineaire multiple etait generalement moins performante que les autres approches, mais etait en mesure d’egaler leur performance dans des regions arides.
Proximité spatiale
Les méthodes de proximité spatiale diffèrent des approches de régression puisqu’elles transfèrent des jeux de paramètres entiers, conservant la coherence entre les parametres. Son mode de fonctionnement est base sur l’utilisation des parametres du modele hydrologique cale sur le bassin versant le plus pres du site non-jauge. L’hypothese de cette methode est que les bassins adjacents possedent des caracteristiques physiques similaires (couverture vegetale, type de sol, etc.) et, par consequent, ont des regimes hydriques comparables. Elle ne necessite donc pas de descripteurs physiques, outre la latitude et la longitude. La premiere etape consiste a classer l’ensemble des bassins versants ou le modele a ete prealablement cale en ordre croissant de distance entre ceux-ci et le bassin non-jauge. Cette distance est habituellement calculee entre les centroides des bassins, selon la formulation suivante : ou d est la distance entre centroides, XG et YG sont respectivement la longitude et la latitude du bassin jauge et XU et YU sont respectivement la longitude et la latitude du bassin nonjauge. Le bassin minimisant la distance d est selectionne en tant que bassin donneur. La figure 2.2 schematise le concept derriere la methode de proximite spatiale. Les formes geometriques a la figure 2.2 representent des bassins versants.
Les bassins selectionnes sont en bleu, les autres sont en gris. La methode de proximite spatiale selectionne les bassins versants les plus pres pour le transfert de parametres. Le cercle pointille gris montre que les bassins sont selectionnes en ordre de distance geographique. Les parametres du modele hydrologique optimise sur le bassin donneur sont ensuite transferes au bassin non-jauge, sur lequel le modele sera execute. Ceci permet de conserver une coherence entre les parametres. Cette methode est utilisee lorsqu’il y a une forte densite de bassins versants (Parajka et al. 2005, Oudin et al. 2008) ou lorsqu’il y a peu de descripteurs physiques disponibles. La methode de proximite spatiale est candidate aux techniques de moyenne des debits afin d’ameliorer la qualite des simulations, tel que decrit a la section 2.2.
Autres méthodes
Outre ces trois approches classiques, certaines autres propositions ont ete apportees dans la litterature. La plus commune est l’approche par krigeage, ou les parametres des modeles sont interpoles dans l’espace selon leur correlation spatiale. D’excellents resultats ont ete rapportes dans la litterature (Vandewiele et Elias 1995, Parajka et al. 2005). Cependant, les modeles utilises dans ces etudes etaient generalement de dimensionnalite restreinte (11 parametres et moins) et les bassins versants tres rapproches. Par exemple, Parajka et al. (2005) ont trouve que le krigeage etait la meilleure approche de regionalisation sur 320 bassins versants en Autriche. En contrepartie, certains auteurs ont montre que le krigeage n’etait pas la meilleure approche. Par exemple, Samuel et al. (2011) ont utilise la methode du krigeage sur 94 bassins en Ontario, Canada. Ils ont trouve que le krigeage performait de maniere equivalente ou legerement inferieure a l’approche de proximite spatiale ponderee par l’inverse de la distance, mais qu’il etait beaucoup plus complexe a mettre en oeuvre. Ces methodes etaient d’ailleurs moins performantes qu’une variante de la proximite spatiale.
De plus, ils ont filtre leurs bassins de maniere a conserver uniquement ceux qui presentent une bonne performance en calage, ce qui pourrait avoir influence les resultats. Une autre technique employee est celle du calage local ou du calage global. Cette approche vise a reduire l’incertitude parametrique en calant l’ensemble des bassins d’une meme region d’un seul coup, trouvant ainsi le meilleur jeu de parametres commun (Ricard et al. 2013). Un bassin non-jauge se trouvant dans cette region recoit le meme jeu de parametres que les autres bassins de sa region. Cette methode comporte deux desavantages. Premierement, elle ne permet pas de differencier certaines caracteristiques propres aux bassins individuels, donnant ainsi lieu a une qualite moindre en calage. En validation et en regionalisation, cette methode repose sur l’hypothese que les caracteristiques des bassins versants de la region sont similaires. Une variante de cette methode est de caler les bassins independamment les uns des autres, puis de moyenner la valeur des parametres au site non-jauge se trouvant dans la dite region. Ceci neglige egalement l’interaction parametrique.
Les resultats sont souvent decevants selon cette methode (Parajka et al. 2005, 2013). Il existe, en parallele, une categorie de methodes ne necessitant pas de modele hydrologique pour prevoir les apports aux sites non-jauges. Ces methodes requierent des series completes a transferer et necessitent generalement une forte densite de bassins afin de preserver le lien climatologique entre le bassin versant donneur et le bassin non-jauge. Parmi ces approches, on peut noter les reseaux de neurones artificiels (Goswami et al. 2007), les ratios des aires contributrices et des courbes de duree-frequence (Mohamoud 2008). Plusieurs variantes des methodes enumerees ici sont detaillees dans Razavi et al. (2013) et He et al. (2011) mais ne seront pas traitees dans cette these en raison de leurs similitudes intrinseques.
Donneurs multiples
Les methodes de regionalisation basees sur les bassins donneurs ont l’avantage de conserver la coherence des parametres lors du transfert au site non-jauge. Cependant, suivant l’approche classique, seule l’information d’un seul donneur est prise en compte, contrairement a la methode de regression lineaire. Pour pouvoir tirer profit d’une certaine diversite des bassins dans ces approches de regionalisation, il est possible d’utiliser plusieurs donneurs. Trois methodes sont couramment employees pour y parvenir. Les figures 2.2 et 2.3 ont deja montre la demarche pour selectionner les bassins versants donneurs. La premiere est la moyenne des parametres des donneurs (Oudin et al. 2008). Elle repose sur l’idee que de simuler un seul hydrogramme base sur la moyenne des parametres permet de reduire l’erreur sur l’estimation du parametre optimal.
Cependant, cette methode requiert idealement une independance parametrique du modele afin que la moyenne des parametres represente adequatement les processus hydrologiques physiques. Ainsi, les valeurs des parametres de i donneurs sont moyennees et fournies au modele pour ne produire qu’un seul hydrogramme generee par le jeu de parametres moyen. La seconde approche, la moyenne arithmetique des apports simules issus des donneurs, permet de conserver la coherence parametrique incluant les correlations croisees entre parametres (Oudin et al. 2008, Viney et al. 2009).
Dans ce cas, le modele hydrologique est execute au site non-jauge autant de fois qu’il y a de donneurs en utilisant a chaque iteration le jeu de parametres optimal du bassin donneur. Il y a donc autant d’hydrogrammes simules que de bassins donneurs. La derniere etape est de calculer la moyenne arithmetique des hydrogrammes simules. Ceci permet de profiter de la diversite de l’ensemble et de reduire l’impact de simulations individuelles de pietre qualite. Par contre, l’ajout de trop de donneurs differents peut reduire la qualite de la simulation.
La derniere approche est la suite logique de la moyenne arithmetique des apports simules, laquelle est remplacee par une moyenne ponderee par l’inverse de la distance des hydrogrammes simules (Samuel et al. 2011, Zhang et Chiew 2009). Le bassin le plus pres (ou le plus similaire) est donc pondere plus fortement que le second, et ainsi de suite. La distance utilisee dans la ponderation est soit la distance geographique pour la methode de proximite spatiale ou la distance de similitude pour la methode de similitude physique. Ceci assure que les bassins donneurs les plus eloignees (ou les moins similaires) ne soient pas consideres de facon aussi importante que les bassins les plus pres (ou les plus similaires).
|
Table des matières
CHAPITRE 1 INTRODUCTION GÉNÉRALE
1.1 Problématique de la thèse
1.2 Organisation de la thèse
CHAPITRE 2 REVUE DE LITTÉRATURE
2.1 Prévision des apports aux sites non-jaugés
2.1.1 Régression linéaire multiple
2.1.2 Proximité spatiale
2.1.3 Similitude physique
2.1.4 Autres méthodes
2.2 Donneurs multiples
2.3 Analyse des approches de régionalisation
2.4Problèmes constatés en régionalisation
2.5 Solutions potentielles
2.5.1Amélioration du calage
2.5.2 Réduction du nombre de paramètres
2.5.3 Modélisation multi-modèle
CHAPITRE 3 ARTICLE 1 : A COMPARISON OF STOCHASTIC OPTIMIZATION ALGORITHMS IN HYDROLOGICAL MODEL CALIBRATION
3.1Introduction
3.2 Optimization algorithms used in the study
3.2.1Adaptive Simulated Annealing (ASA
3.2.2Covariance Matrix Adaptation Evolution Strategy (CMAES
3.2.3 Cuckoo Search (CS)
3.2.4 Dynamically dimensioned search (DDS)
3.2.5Differential Evolution (DE
3.2.6Genetic Algorithm (GA
3.2.7 Harmony Search (HS)
3.2.8Pattern Search (PS
3.2.9 Particle Swarm Optimization (PSO)
3.2.10Shuffled Complex Evolution – University of Arizona (SCE-UA
3.3Models, study area and data
3.3.1 Hydrologic models
3.3.2 Basins
3.4 Benchmarking of the optimization methods
3.5Results
3.5.1Algorithm performance based on ranks
3.5.2Algorithm performance based on convergence speed
3.5.3 Statistical significance tests
3.5.4 Dispersion Metric
3.6 Discussion
3.6.1 On overall performance
3.6.2 On model complexity
3.6.3On the effect of the basin on algorithm performance
3.6.4On convergence speed
3.6.5 On computing power
3.7 Conclusion
3.8Acknowledgements
3.9References
CHAPITRE 4 ARTICLE 2 : A COMPARATIVE ANALYSIS OF 9 MULTI-MODEL AVERAGING APPROACHES IN HYDROLOGICAL CONTINUOUS STREAMFLOW SIMULATION
4.1Introduction
4.2Data, models and multi-model averaging methods
4.2.1Basins, hydrometric and climate data
4.2.2 Hydrological models
4.2.3Multi-model averaging methods
4.2.4Model calibration
4.2.5 Multi-model averaging application
4.3Results
4.3.1Performance of the 15 ensemble members
4.3.2 Performance of the multi-model averaging methods
4.3.3Performance gain quantification
4.3.4Geographical analysis
4.4 Discussion
4.4.1 Individual model performance
4.4.2 Multi-model averaging method analysis
4.4.3 Member contribution in multi-model averaging
4.4.4Geographic analysis
4.5 Conclusion
4.6Acknowledgements
4.7References
CHAPITRE 5 ARTICLE 3 : IMPROVING HYDROLOGICAL MODEL SIMULATIONS USING MULTIPLE GRIDDED CLIMATE DATASETS IN MULTI-MODEL AND MULTI-INPUT AVERAGING FRAMEWORKS
5.1Introduction
5.2Catchments and data
5.3 Models and Methodology
5.3.1 Hydrological models
5.3.2Model parameter calibration process
5.3.3 Model averaging technique
5.3.4Multi-model and multi-input averaging application
5.4Results
5.5 Discussion
5.5.1 Results analysis
5.5.2 Pre-averaging of climate data
5.5.3 Possible further improvements
5.6 Conclusion
5.7Acknowledgements
5.8References
CHAPITRE 6 ARTICLE 4 : CONTINUOUS STREAMFLOW PREDICTION IN UNGAUGED BASINS : THE EFFECTS OF EQUIFINALITY AND PARAMETER SET SELECTION ON UNCERTAINTY IN REGIONALIZATION APPROACHES
6.1Introduction
6.1.1 Equifinality
6.2Scope and aims
6.3 Study area and data
6.3.1 Study area
6.3.2 Meteorological and hydrological datasets
6.4 Methodology
6.4.1 HSAMI hydrological model and calibration
6.4.2 Uncertainty analysis
6.4.3 Generalities common to all regionalization methods
6.4.4Multiple linear regression regionalization method
6.4.5 Physical similarity regionalization method
6.4.6 Spatial proximity regionalization method
6.4.7Regression-augmented approach
6.5Results
6.5.1 Regression-based approach
6.5.2Physical similarity approach
6.5.3 Spatial proximity
6.5.4 Inverse distance weighting
6.5.5 Regression-augmented
6.5.6Inter-method comparison
6.5.7Success Rate vs. Nash-Sutcliffe Efficiency
6.5.8Hydrograph analysis
6.6 Discussion
6.6.1 Number of donor catchments
6.6.2 Regionalization methods analysis
6.6.3 Comparison with other studies
6.6.4 Parameter set selection uncertainty
6.6.5 Type I errors in hypothesis testing
6.7Conclusions
6.8Acknowledgments
6.9References
CHAPITRE 7 ARTICLE 5 : MULTI-MODEL AVERAGING FOR CONTINUOUS STREAMFLOW PREDICTION IN UNGAUGED BASINS
7.1Introduction
7.1.1 Multi-model averaging
7.1.2 Multi-model averaging in regionalization
7.1.3 Averaging methods description
7.2Models, study area and data
7.2.1 Hydrological models
7.2.2 Study area
7.2.3 Meteorological and hydrological datasets
7.3 Methodology
7.3.1Model calibration
7.3.2 Donor basin selection scheme
7.3.3Model averaging strategies
7.3.4Multi-donor averaging
7.4Results
7.4.1 Initial model calibration and weighting method evaluation
7.4.2Regionalization under the multi-model averaging framework
7.4.3 Weights distribution
7.5 Analysis and discussion
7.5.1 Overview of model averaging methods performances
7.5.2 Multi-model averaging in regionalization
7.5.3Model robustness
7.5.4Multi-donor aspect
7.6Conclusions
7.7Acknowledgments
7.8References
CHAPITRE 8 ARTICLE 6 : ANALYSIS OF CONTINUOUS STREAMFLOW REGIONALIZATION METHODS USING A REGIONAL CLIMATE MODEL ENVIRONMENT FRAMEWORK
8.1Introduction
8.2Data and Methodology
8.2.1 Description of the virtual-world setting
8.2.2 Meteorological data
8.2.3 Virtual-world setting hydrometric data
8.2.4 Catchment descriptors
8.2.5 HSAMI hydrological model
8.2.6Model Calibration
8.2.7 Regionalization methods
8.2.8Methodology
8.3Results
8.4Analysis
8.4.1Real world and CRCM environment
8.4.2 Analysis of the methods performance
8.4.3 Evaluation metrics and donor quality analysis
8.4.4Predicting probability of success
8.5 Conclusion
8.6Acknowledgements
8.7References
CHAPITRE 9 ARTICLE 7 : PARAMETER DIMENSIONALITY REDUCTION OF A CONCEPTUAL MODEL FOR STREAMFLOW PREDICTION IN UNGAUGED BASINS
9.1Introduction
9.2Scope and aims
9.3 Study area and data
9.3.1 Meteorological and hydrological datasets
9.4 Methodology
9.4.1 Hydrological models
9.4.2Model calibration
9.4.3 Sobol’ Global sensitivity analysis
9.4.4Sequential model parameter fixing and recalibration
9.4.5 Regionalization methods application
9.5Results
9.5.1 Model calibration performance
9.5.2Regionalization application results
9.5.3 Robustness evaluation
9.6 Discussion
9.6.1 Verification of the main hypothesis
9.6.2 Sobol’ sensitivity analysis
9.6.3 Parameter fixing
9.6.4 Regionalization performance
9.7Conclusions
9.8 Acknowledgments
9.9 References
CHAPITRE 10 DISCUSSION GÉNÉRALE
10.1Analyse de l’équifinalité en régionalisation
10.2Caractéristiques physiques des bassins versants et paramètres des modèles
10.3Comparaisons entre le monde réel et le monde virtuel
10.4 Analyse des appoches multi-modèle
10.4.1Approches multi-modèle en régionalisation
CONCLUSION ET CONTRIBUTIONS
RECOMMANDATIONS
ANNEXE I ARTICLE EN COLLABORATION 1 : POTENTIAL OF GRIDDED DATA AS INPUTS TO HYDROLOGICAL MODELING
ANNEXE II ARTICLE EN COLLABORATION 2 : REDUCING THE
PARAMETRIC DIMENSIONALITY FOR RAINFALL-RUNOFF
MODELS : A BENCHMARK FOR SENSITIVITY ANALYSIS METHODS
ANNEXE III LISTE DES CONTRIBUTIONS SCIENTIFIQUES
LISTE DE RÉFÉRENCES BIBLIOGRAPHIQUES