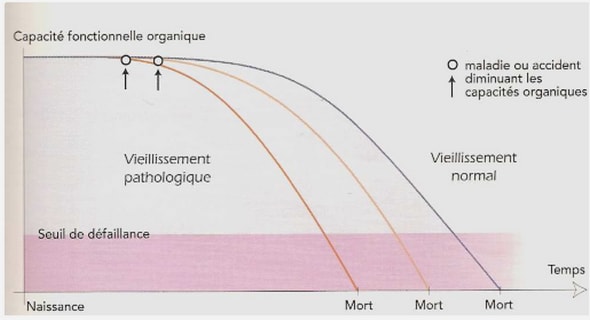
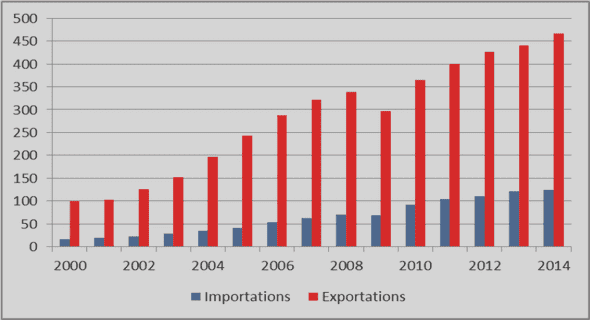
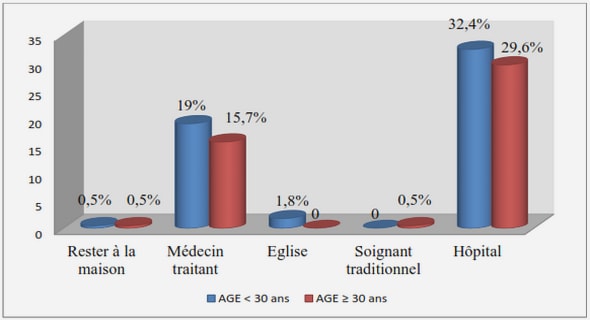
Télécharger le fichier pdf d’un mémoire de fin d’études
Les bases de données d’interactions protéine-protéine
Pour collecter, classer et rendre accessible ces différentes données expérimentales issues de l’analyse des interactions protéines-protéines, différentes bases de données ont été développées. Leà différents outils d’analyse de séquences, de domaines ou de préditions d’interaction extrêmement utiles pour accéder à un état des connaissances complet pour une protéine d’intérêt. Ces différences de traitements font que ces bases de données peuvent contenir des nombres très différents d’interactions. À titre d’exemple, la base de données BIND contient 188517 interactions, et la base de données DIP n’en possède que 56186.
Méthodes de prédiction des interactions protéines-protéines
Introduction
Face aux masses de données générées par les projets de séquençage de différents organismes, un des défis les plus importants de l’ère post-génomique consiste à exploiter ces informations, afin de prédire des interactions fonctionnelles entre protéines. Une approche globale consiste à utiliser des méthodes bioinformatiques pour comparer les protéomes de différents organismes et prédire des interactions fonctionnelles directes ou indirectes entre protéines.
Dans cette section, je présenterai différentes approches bioinformatiques destinées à prédire les interactions entre protéines : (i) les méthodes d’inférence génomique, (ii) les méthodes basées sur la co-évolution des protéines, (iii) les méthodes de classification.
Les méthodes d’inférences génomiques
Inférence d’interactions protéine-protéine : la notion d’interologues. En supposant que des protéines interagissant dans un organisme donné ont coévolué de façon à ce que leurs orthologues respectifs interagissent de la même façon au sein d’autres organismes, Walhout et collaborateurs ont introduit en 2000 la notion d’interaction conservée ou « interologues » (Walhout et al., 2000). La définition est la suivante : « en considérant deux protéines A et B connues pour interagir dans un organisme, si on trouve des orthologues A’ et B’ dans un autre organisme, A-B et A’-B’ sont considérés comme des intérologues ». Chez C. elegans, Walhout et collaborateurs ont montré qu’environ 7% des interactions possédaient des interologues décrits dans la littérature.
Sur la base de cette considération, une étude réalisée par Matthews et collaborateurs, s’est focalisée sur une recherche d’interologues à grande échelle pour inférer des interactions protéine-protéine connues (Matthews et al., 2001). Les auteurs ont voulu évaluer à quel point une carte d’interactions protéiques décrite chez S. cerevisiae pouvait permettre la prédiction d’interactions par inférence chez C. elegans. Les auteurs ont estimé entre 16% et 31% le pourcentage minimum d’interactions vraies prédites par ce genre d’approche, ce qui a été confirmé par une étude plus récente (Yu et al., 2004).
Evènements de fusions de gènes : la méthode « Rosetta Stone ». Certaines études ont montré qu’on retrouvait des homologues entre certaines paires de protéines en interaction fusionnées en une seule protéine (Berger et al., 1996; Enright et al., 1999; Marcotte et al., 1999). Il a donc été proposé que deux protéines A et B dans un même organisme interagissent si leurs homologues se retrouvent exprimés au sein d’une même protéine dans une autre espèce (Figure 5).
Appliquée au génome d’E. Coli, cette méthode a permis de sélectionner 6809 paires de protéines potentiellement en interaction. Parmi les 3950 paires dont la fonction a été caractérisée, 68% des paires sont liées au niveau de leur fonction (Marcotte et al., 1999). De plus, les auteurs ont montré que 6.4% des interactions caractérisées sur le plan expérimental au niveau de la base de données DIP sont prédites par l’approche Rosetta Stone.
Conservation du voisinage physique des gènes. Après une étude de l’organisation des génomes de H. influenza et d’E. Coli, Tamames et collaborateurs ont conclut que les gènes liés fonctionnellement dans ces espèces étaient le plus souvent regroupés au sein de certaines régions proches particulièrement conservées, ce qui supposerait un lien direct entre une interaction physique et une conservation de l’ordre des gènes (Tamames et al., 1997). À titre d’exemple, dans les génomes procaryotes, certains gènes liés fonctionnellement, et codant des protéines qui interagissent potentiellement sont regroupées au sein de ce qu’on appelle des opérons.
En 1998, Dandekar et collaborateurs ont proposé que cette conservation de la proximité des gènes fonctionnellement liés, permettrait de prédire des interactions physiques entre 27 protéines (Dandekar et al., 1998). Le principe consiste à prédire une interaction entre les gènes physiquement proches dans les génomes de plusieurs organismes (Figure 6). Appliqué
à l’étude de certains génomes bactériens et archaebactériens, les auteurs ont montré que 75% des paires de protéines prédites en interaction par cette approche interagissent physiquement. Des résultats similaires ont été également reportés dans d’autres génomes eucaryotes : S. cerevisiae et C. elegans (Teichmann and Babu, 2002).
Les profils phylogénétiques. En 1999, Pellegrini et collaborateurs ont introduit la notion de profils phylogénétiques pour identifier les protéines reliées à une même fonction (Pellegrini et al., 1999). Ce concept se base sur l’hypothèse qu’au cours de l’évolution, les protéines liées à une même fonction ont tendance à être préservées ou éliminées de façon corrélée au sein d’une espèce. Les auteurs décrivent cette propriété de co-évolution, en caractérisant chaque protéine par un « profil phylogénétique ». En considérant n espèces, le profil phylogénétique d’une protéine donnée est alors représenté sous forme d’un vecteur à n entrées, chaque entrée prenant comme valeur 1 ou 0 en fonction de la présence ou de l’absence d’un homologue de la protéine pour une espèce donnée (Figure 7).
En comparant les profils phylogénétiques de toutes les paires d’un sous ensemble de 1231 protéines chez E. coli et 1131 protéines chez S. cerevisiae dont la fonction est connue, Date et Marcotte ont montré que la similarité des profils génétiques étaient hautement corrélée à une similarité fonctionnelle des protéines (Date and Marcotte, 2003).
Les méthodes de co-évolution
Similarité des arbres phylogénétiques. Différentes études ont montré que la similitude entre les arbres phylogénétiques de deux protéines en interaction était un marqueur de leur co-évolution (Fryxell, 1996). À titre d’exemple, un coefficient de corrélation de 0.79 a été reporté entre les arbres phylogénétiques des deux domaines protéiques N- et C-terminaux de la protéine kinase PGK (Goh et al., 2000). Des coefficients de corrélations très proches ont également été publiés par l’équipe de Valencia sur une base de données de 13 interactions domaine-domaine intra-moléculaires, ce qui suggère une pression évolutive et une co-adaptation très forte entre des domaines structuraux d’une même protéine (Pazos and Valencia, 2001). Les auteurs ont quantifié la similarité des arbres phylogénétiques des interactants en calculant le coefficient de corrélation linéaire entre les matrices de distances utilisées pour construire les arbres (Figure 8).
Par l’analyse de différentes bases de données d’interactions, les auteurs de cette étude ont observé le même type de signal de co-évolution entre des interactions de types intramoléculaires ou inter-moléculaires, et proposent un coefficient de corrélation seuil de 0.8 comme un bon critère pour la prédiction d’interactions protéine-protéine. Le potentiel de cette approche pour la prédiction d’interactions protéine-protéine a été confirmé par une étude portant sur six familles d’interactions ligand-récepteur (Goh and Cohen, 2002).
En 2005, une mise à jour de l’approche, consistant à intégrer explicitement l’histoire évolutive des espèces pour prendre en compte les similarités entre l’arbre phylogénétique des protéines et des espèces (Pazos et al., 2005), et plus récemment l’intégration de certains algorithmes basés sur des machines à vecteur de support (SVM) (Craig and Liao, 2007) ont considérablement amélioré les qualités prédictives de la méthode.
La méthode double hybride in-silico (i2h). La présence de mutations compensatoires au sein de complexes protéiques est un phénomène d’adaptation révélateur d’une trace de leur co-évolution. Mises en évidence en dans les années 90 au sein de protéines globulaires (Gobel et al., 1994), elles permettraient de conserver la structure des protéines malgré leur taux d’évolution important, ce qui expliquerait que les structures des protéines puissent être plus conservées que leur séquences (Chothia and Lesk, 1986).
Le principe fondamental repose sur l’hypothèse qu’une mutation survenant à une position de la séquence d’une protéine, doit être compensée par une seconde mutation concernant une position voisine au niveau structural. Sur la base de ce principe, l’équipe de A. Valencia a développé en 2002 une nouvelle méthode basée sur la détection de mutations corrélées pour la prédiction in silico des interactions protéine-protéine : la méthode « i2h » (double hybride in silico) (Pazos and Valencia, 2002). L’objectif de cette méthode est non seulement de prédire les interactions physiques entre protéines, mais aussi d’identifier les régions impliquées dans ces interactions. Le principe de la méthode est illustré Figure 9. Les auteurs de cette étude ont définit un seuil empirique de 2.0 comme étant un bon indicateur d’une interaction physique entre deux protéines.
Figure 9. La méthode double hybride in-silico (i2h). (A) Alignements de séquences de deux protéines 1 et 2. (B) Concaténation des deux alignements de séquences, et calcul des coefficients de corrélation pour chaque paire de résidus au sein de la protéine 1 (P11), de la protéine 2 (P22), ou entre les protéines 1 et 2 (P12). (C) À partir des distributions des valeurs de corrélation P11, P22 et P12, un indice d’interaction est calculé. Figure extraite de (Pazos and Valencia, 2002).
Les méthodes de classification
Les méthodes de classification se basent sur différentes sources de données pour réaliser un apprentissage des différentes caractéristiques qui distinguent des paires de protéines en interaction ou non. Dans le cas de la prédiction des interactions protéine-protéine, la comparaison de différentes méthodes de classification a montré que l’approche la plus efficace est la méthode « Random Forest Decision » (RFD) (Qi et al., 2006).
Le principe des méthodes RFD est la construction d’arbres de décision basés sur la composition en domaines de protéines interagissant ou n’interagissant pas entre elles (Chen and Liu, 2005). À partir d’un ensemble de données regroupant des paires de protéines connues pour interagir, la méthode construit un arbre de décision qui traduit la meilleure discrimination entre des protéines qui interagissent ou n’interagissent pas entre elles. En visitant l’arbre de décision, il est alors possible de prédire si deux protéines P1 et P2 interagissent ou non.
Dynamique et logique moléculaire au sein des réseaux d’interaction protéine-protéine
Dynamique des réseaux contrôlés par l’expresion des partenaires.
Les cartes d’interactions protéine-protéine offrent une perception relativement statique des processus cellulaires. Pourtant, comme nous l’avons mentionné précédemment, les procesus d’assemblages s’avèrent souvent très dynamiques aussi bien dans la formation des machineries cellulaires que pour l’activation des complexes de signalisation. Un travail remarquable réalisé par les équipes de Bork et Brunak illustre particulièrement bien le caractère dynamique de ces réseaux d’interactions (de Lichtenberg et al., 2005).
les propriétés temporelles d’assemblage des complexes du cycle cellulaire dans trois organismes, H. sapiens, S. cerevisiae et S. pombe (Jensen et al., 2006). Pour être vraiment effectif ce contrôle transcriptionnel doit s’accompagner d’un contrôle au niveau de la dégradation des protéines. Ce dernier exemple indique qu’il doit exister des mécanismes de co-évolution entre les processus de régulation transcriptionnelle et de dégradation protéique afin de maintenir un contrôle de l’assemblage des complexes.
Dynamique des réseaux de signalisation et reconnaissance des motifs linéaires.
Une des clés pour appréhender la plasticité des réseaux d’interactions protéiques au cours de l’évolution se situe probablement dans l’analyse des mécanismes de communication entre machineries cellulaires au niveau des mécanismes de transduction des signaux. Au sein de la cellule, la transduction des signaux est souvent médiée par des interactions entre des protéines modulaires. Il apparaît que certaines de ces interactions sont régulées par des domaines spécialisés, capables d’interagir avec des protéines, des phospholipides, des petites molécules ou des acides nucléiques. Il est maintenant bien établi que de tels domaines médiateurs d’interactions, appelés également domaines régulateurs, jouent un rôle fondamental dans l’organisation et la coordination des réponses cellulaires suite à différents stimuli (Pawson and Nash, 2003).
Une des propriétés remarquable d’une majorité de ces domaines médiateurs d’interactions est de reconnaître de courts fragments protéiques (ces domaines sont appelés des« Peptide Recognition Modules » (PRMs)), ou encore de former des assemblages moléculaires de type domaine-domaine. Parmi les PRMs impliqués dans les voies de transduction du signal, plusieurs d’entre eux sont capables de reconnaître certains motifs peptidiques bien précis (Figure 12).
Caractérisation structurale et propriétés descomplexes protéiques
Introduction
La présence d’un nombre croissant de structures de complexes au sein de la PDB a permis à différentes équipes d’étudier les interfaces de complexes protéiques, afin d’en extraire les propriétés géométriques, physico-chimiques mais aussi évolutives.
Propriétés géométriques des interfaces de complexes
La taille des interfaces de complexes protéiques est généralement mesurée par la différence entre l’aire de la surface accessible (ASA) du complexe et celle des partenaires libres. Si on considère deux protéines A et B s’associant sous forme d’un complexe, la surface de contact est définie par : S = ASAprotA + ASAprotB – ASAcomplexeAB
En 1999, l’équipe de J. Janin a analysé les caractéristiques structurales de 75 complexes protéiques, et plus particulièrement la taille de leurs interfaces. Les complexes analysés regroupent entre autres des complexes de type protéase-inhibiteur, anticorps-antigène, enzyme-inhibiteur ou encore d’autres complexes impliqués dans la transduction du signal (Lo Conte et al., 1999). Par cette étude, les auteurs ont montré qu’une grande proportion de ces assemblages, principalement des complexes de type protéase-inhibiteur ou antigène-anticorps, ont une interface dont la taille est de 1600 (+/-400) Å2. D’autres complexes ont la particularité de présenter des interfaces de liaison particulièrement importantes, allant de 2000 à 4660 Å2. Les protéines constitutives de ces complexes ont de plus la caractéristique de subir des changements conformationnels importants au cours de leur assemblage, à l’inverse des complexes protéiques de taille standard (Lo Conte et al., 1999).
En outre, il semblerait que la taille des interfaces de complexes soit reliée au caractère transitoire ou permanent des assemblages protéiques. En effet, il apparaît que les tailles des interfaces de complexes permanents sont plus importantes que celles des complexes transitoires (Jones and Thornton, 1996; Lo Conte et al., 1999).
Propriétés physico-chimiques des interfaces de complexes protéiques
Les propriétés physico-chimiques des interfaces de complexes protéiques ont été étudiées afin de déterminer les contributions majeures à la stabilité des interfaces.
Glaser et collaborateurs ont démontré, en analysant une base de données de 621 interfaces de complexes protéiques, regroupant entre autres des oligomères ou des complexes enzyme-inhibiteur, que la plupart des contacts entre paires de protéines aux interfaces de complexes impliquaient de larges résidus hydrophobes (Glaser et al., 2001). En outre, les auteurs ont remarqué une différence significative de la composition des interfaces entre de petites et de grosses interfaces. En effet, il apparaît que les résidus hydrophobes sont souvent retrouvés au sein de grosses interfaces, alors que les résidus polaires prévalent dans les petites interfaces. Compte tenu de ces résultats, il apparaît que l’effet hydrophobe, jouant un rôle primordial dans le repliement des protéines, a également un rôle majeur dans la stabilisation des complexes protéiques (Glaser et al., 2001). Les interactions électrostatiques et hydrophobes seraient les propriétés physico-chimiques qui contribuent le plus à la stabilité des complexes protéiques (McCoy et al., 1997; Sheinerman et al., 2000).
Un des aspects non appréhendé par l’étude de Glaser et collaborateurs concerne la distinction entre les complexes permanents et les complexes transitoires. Or en fonction du type de complexes, les forces qui régissent leur interaction sont différentes. En effet, il a été montré que les interfaces de complexes permanents étaient généralement plus hydrophobes que les interfaces de complexes transitoires (Carugo and Argos, 1997; Larsen et al., 1998).
Récemment, De et collaborateurs sont allés plus loin dans la comparaison des complexes permanents et transitoires, en analysant les différences de propriétés au cœur et en périphérie de ces interfaces (De et al., 2005). Ils ont en particulier montré que la périphérie des interfaces de complexes permanents et transitoires est de nature plus polaire que le cœur de ces interfaces. En outre, ils ont confirmé que les interfaces de complexes transitoires sont plus polaires que les interfaces de complexes permanents, aussi bien au cœur qu’en périphérie. Cette propriété peut s’expliquer par le fait que les résidus à l’interface des complexes transitoires interagissent avec le solvant lorsque les protéines constitutives de ce type de complexe existent sous leur forme libre. Afin d’analyser la contribution de chaque type de résidus à la stabilisation d’un complexe protéique, Bogan et Thorn ont étudié plus précisément leur influence sur l’énergie de liaison (Bogan and Thorn, 1998). Pour cela, les auteurs ont analysé au sein d’une base de données de complexes protéiques d’hétérodimères, la contribution énergétique de chaque résidu dans la stabilisation de ces complexes. Par cette étude, ils ont montré que l’énergie de liaison n’est pas distribuée de façon uniforme sur une interface, mais qu’il existe certains résidus, appelés « hot spots », dont la mutation conduit à une chute significative de l’affinité de liaison. Il apparaît que ces « hot spots », principalement des tryptophanes, tyrosines et arginines, sont localisés préférentiellement au cœur des interfaces de complexes, et entourés de résidus dont le rôle serait de les exclure du solvant. Cette exclusion du solvant permettrait ainsi une diminution de la constante diélectrique, et aurait donc pour effet d’augmenter la force des interactions électrostatiques et des liaisons hydrogènes (Bogan and Thorn, 1998). Des analyses complémentaires concernant ces positions particulièrement importantes pour la spécificité de reconnaissance des assemblages protéiques, ont par la suite montré que ces résidus étaient particulièrement bien conservés (Halperin et al., 2004; Hu et al., 2000).
Propriétés évolutives des interfaces de complexes protéiques
Le nombre croissant de données génomiques et structurales disponibles dans les banques de données a permis récemment d’entreprendre les premières études systématiques dans le but d’explorer les relations entre similarité de séquences et similarité de structures des complexes protéiques. L’objectif de ces études était alors de mieux appréhender les mécanismes d’évolution des interfaces de complexes protéiques.
En 2003, l’équipe de Russell a entrepris l’étude à grande échelle de structures de complexes protéiques domaine-domaine intra-moléculaires et inter-moléculaires caractérisés sur le plan expérimental (Aloy et al., 2003). En comparant les structures de complexes homologues selon la classification SCOP (Murzin et al., 1995), cette étude a révélé que les homologues proches (à plus de 30% en identité de séquence) interagissent de la même façon sur le plan structural. Les résultats de cette étude, portant sur plus de 30000 interactions, suggèrent ainsi qu’en dessous de 30% d’identité, les interactions entre protéines homologues peuvent différer complètement (Figure 18). Une seconde étude plus récente, portant sur plus de 4000 interactions domaine-domaine non redondantes, a confirmé ce résultat, et conclut que les 42 positions relatives des résidus situés aux interfaces de complexes protéiques sont généralement conservés même chez des homologues lointains (Kim and Ison, 2005).
|
Table des matières
Sommaire
Chapitre 1 : Introduction Générale
1.1. Les interactions protéine-protéine
1.1.1. Introduction
1.1.2. Nature et dynamique d’assemblage des complexes protéiques
1.1.3. Mise en évidence des interactions protéine-protéine
1.1.4. Les bases de données d’interactions protéine-protéine
1.2. Méthodes de prédiction des interactions protéines-protéines
1.2.1. Introduction
1.2.2. Les méthodes d’inférences génomiques
1.2.3. Les méthodes de co-évolution
1.2.4. Les méthodes de classification
1.3. Dynamique et logique moléculaire au sein des réseaux d’interaction protéine-protéine
1.3.1. Dynamique des réseaux contrôlés par l’expression des partenaires
1.3.2. Dynamique des réseaux de signalisation et reconnaissance des motifs linéaires.
1.3.3. Intégration des signaux intra-cellulaires par des interactions de type domaine-domaine
1.3.4. Peut-on reproduire artificiellement la logique moléculaire ?
1.4. Caractérisation structurale et propriétés des complexes protéiques
1.4.1. Introduction
1.4.2. Propriétés géométriques des interfaces de complexes
1.4.3. Propriétés physico-chimiques des interfaces de complexes protéiques
1.4.4. Propriétés évolutives des interfaces de complexes protéiques
1.5. Méthodes bioinformatiques pour la prédiction des structures de complexes protéines-protéines
1.5.1. Introduction
1.5.2. Modélisation comparative des structures de complexes protéiques
1.5.3. Les techniques d’amarrage moléculaire ou docking
1.6. Design d’interactions protéines-protéines par des approches rationnelles
1.6.1. Introduction
1.6.2. Les méthodes automatiques et semi-automatiques de design
1.6.3. Design d’interfaces protéines-protéines
Chapitre 2 : Prédictions de sites fonctionnels par conservation différentielle
2.1. Introduction
2.2. Mise en évidence de régions fonctionnelles par analyse de conservation : la protéine Nbs1
2.2.1. La protéine NBS1
2.2.2. Mise en évidence de régions fonctionnelles au sein de la protéine Nbs1 par une analyse de conservation manuelle
2.2.3. Mise en évidence de régions fonctionnelles au sein de la protéine Nbs1 par une analyse de conservation automatique : la méthode rate4site
2.2.4. Conclusion
2.3. Prédiction des sites d’interactions protéiques des protéines kinases par analyse différentielle de conservation
2.3.1. Introduction
2.3.2. Principe général de la conservation différentielle
2.3.3. Prédiction des sites d’interactions intra-moléculaires par conservation différentielle : le cas des domaines régulateurs de kinases
2.4. L’analyse différentielle ou comment prédire des changements de spécificité fonctionnelle au sein des protéines : la protéine MsbA
2.4.1. La protéine P-gp et son homologue MsbA
2.4.2. Analyse par conservation différentielle
2.5. Discussion, Conclusions et Perspectives
Chapitre 3 : Analyse des propriétés évolutives des interfaces protéiques intra-moléculaires
3.1. Introduction
3.2. Constitution d’une base de données de complexes intra-moléculaires
3.3. Conservation des interfaces de complexes intra-moléculaires
3.4. Co-évolution des interfaces de complexes intra-moléculaires
3.4.1. Mutations corrélées et mutations compensatoires
3.4.2. Prédominance des événements de mutations compensatoires en périphérie des interfaces
3.5. Maintien de la complémentarité au sein des interfaces de complexes
3.5.1. Maintien de la complémentarité des paires de résidus en contact au sein des interfaces au cours de l’évolution
3.5.2. La prise en compte du contexte structural révèle un maintien de la complémentarité des paires de résidus en contact au cours de l’évolution
3.6. Conclusion
Chapitre 4 : Prédiction des assemblages macromoléculaires
4.1. Introduction
4.2. Constitution des bases de données de complexes protéiques
4.3. Evaluation des capacités discriminatives des méthodes évolutives : le cas des interactions intramoléculaires
4.3.1. Evaluation des différentes approches évolutives
4.3.2. La complémentarité évolutive des interfaces protéiques est-elle un bon critère pour identifier les assemblages protéiques natifs ?
4.4. SCOTCH : une nouvelle méthode pour prédire la structure des assemblages protéiques
4.4.1. Apprentissage supervisé des caractéristiques évolutives des complexes : l’approche SCOTCH
4.4.2. Validation de l’approche SCOTCH pour le cas d’interactions intra-moléculaires
4.4.3. Validation de l’approche SCOTCH pour le cas d’interactions inter-moléculaires
4.4.4. Optimisation de l’approche SCOTCH par un score statistique
4.4.5. Capacités de filtrage de la méthode SCOTCH
4.4.6. Le programme RosettaDock
4.4.7. SCOTCH : une fonction de score efficace pour le docking protéine-protéine
4.5. Obtention de modèles d’assemblages à haute résolution
4.5.1. Introduction
4.5.2. Perturbations locales des structures de complexes
4.5.3. Profil énergétique des structures natives de complexes
4.5.4. Le profil énergétique permet-il d’identifier les structures natives de complexes parmi les structures générées à basse résolution ?
4.6. Applications de la méthode SCOTCH à des complexes étudiés au sein de l’équipe
4.6.1. Application 1 : Modélisation structurale du complexe entre les domaines CS et ATPase de Hsp90
4.6.2. Application 2 : modélisation structurale de l’interaction Asf1 – Histone H3
4.7. Discussion
Chapitre 5 : De la structure à l’inhibition des complexes protéiques
5.1. Introduction
5.2. Inhibition de l’interaction Asf1-Histone H3-H4
5.2.1. Introduction
5.2.2. Optimisation d’un peptide inhibiteur de l’interaction Asf1-Histone H3-H4
5.2.3. Affinité du peptide H3-GAGG-H4 avec la protéine Asf1
5.3. Développements rationnels de vaccins
5.3.1. Introduction
5.3.2. Formation d’un complexe covalent entre la protéine gp120 et un peptide mimétique du récepteur CD4
5.3.3. Design d’une protéine chimère combinant gp120 et CD4M33
5.3.4. Conclusion
Chapitre 6 : Discussion – Perspectives
6.1. Mécanismes évolutifs et interfaces des complexes protéiques
6.2. De la co-évolution à la prédiction de structure des complexes protéiques.
6.3. Un double-hybride in silico basé sur le score SCOTCH ?
6.4. De la prédiction des interfaces protéiques à leur ingénierie
Chapitre 7 : Méthodes
7.1. Prédiction des sites d’interactions protéiques des protéines kinases par analyse différentielle de conservation
7.1.1. Création des alignements de séquences
7.1.2. Analyse de conservation
7.1.3. Analyse de conservation différentielle
7.2. Prédiction des assemblages macromoléculaires
7.2.1. Utilisation des fonctions de score du programme RosettaDock
7.2.2. Le programme SCOTCHer
7.2.3. Application 1 : Modélisation structurale des domaines CS et ATPase de Hsp90
7.2.4. Application 2 : modélisation structurale de l’interaction Asf1 – Histone H3
7.3. Inhibition de l’interaction Asf1-Histone H3-H4
7.4. Développements rationnels de vaccins
7.4.1. Formation d’un complexe covalent entre la protéine gp120 et le peptide CD4M64
7.4.2. Design d’une protéine chimère combinant gp120 et CD4M33
Chapitre 8 : Annexes
8.1. Paramètres des dynamiques moléculaires
8.2. Prédiction des assemblages macromoléculaires
8.2.1. Les quaternions
8.2.2. Le programme SCOTCHer
8.3. Inhibition de l’interaction Asf1-Histone H3-H4
Publications
Bibliographie
Télécharger le rapport complet