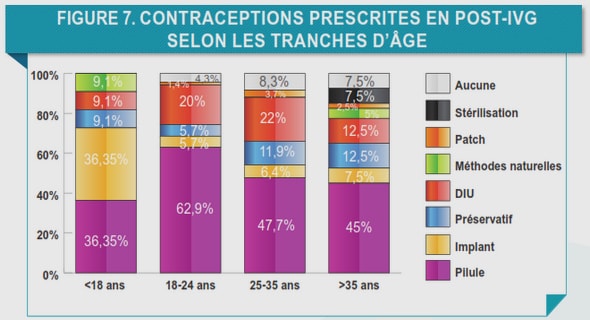
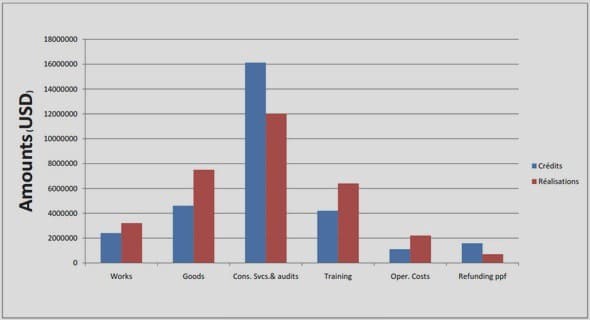
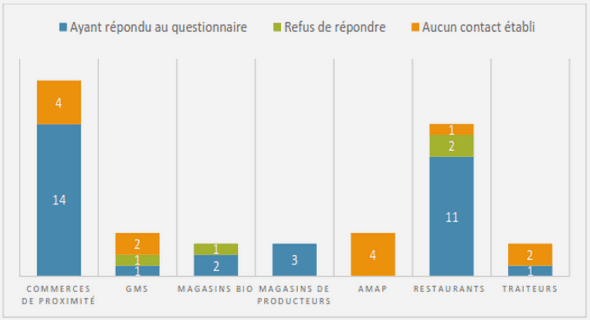
Télécharger le fichier pdf d’un mémoire de fin d’études
Traitement d’images
Techniques de seuillages
Normalisation des images
Localisation des objets liquides
– Seuillage via la forme de l’histogramme.
– Seuillage par transformée en Ondelette.
Le seuillage d’une image consiste à transformer une image en niveau de gris en une image segmentée où chaque classe d’objets possède sa propre valeur de niveau de gris. Dans le cas où seules deux classes existent (fond d’un côté et objets de l’autre), on parle de « binarisation » d’image.
Où ′ est l’image segmentée avec deux niveaux (1 pour le fond lumineux et 0 pour les objets), le seuil normalisé (0 < < 1) déterminant le seuil de niveau de gris dépendant des niveaux de gris maximum et minimum de l’image à segmenter. L’utilisation d’une valeur de seuil plus élevée augmente le nombre d’objets détectés mais augmente également la sensibilité de la segmentation au bruit de fond l’image. Ceci peut se traduire par le regroupement de deux objets proches en 1 seul ou encore par l’apparition de taches dans le fond lumineux, comme l’illustre la figure 30.
La détermination du contour pixel peut être suffisante pour les images issues de caméra à haute résolution. La particularité de la méthode développée au CORIA est que le seuil de niveau de gris utilisé dans l’équation (81) sera ici déterminé localement pour chacun des objets labélisés étudiés. Ce seuil dépendra des niveaux et locaux à la portion d’image correspondant à cet objet et une correction est appliquée en fonction du défaut de mise au point de l’objet (Fdida et al. (2009)). Cette segmentation est calibrée pour placer le contour des objets au plus près de la position de l’interface.
– Segmentation directe de l’image au niveau sub-pixel.
– Reconstruction sur-résolue de l’image complète, puis segmentation classique.
La segmentation directe au niveau sub-pixel va chercher à interpoler un contour sub-pixel local et retourner une image segmentée sub-pixel. La plupart des méthodes sont basées sur les modèles itératifs à contours déformables, dit « snake ». Ils ont été introduit par Kass et al. (1988) pour le cas d’images 2D avant d’être rapidement généralisé en 3D (Li et al. (2010), Terzopoulos et al. (1988)). Ces méthodes sont basées sur la déformation d’une ligne spline (appelée level-set) qui respecte un critère de minimisation d’énergie (force interne au contour) et se déplace dans l’image jusqu’aux contours en fonctions des attributs (gradients de niveaux de gris, textures, …) de l’image (force externe au contour).
Initialement, ces méthodes level-set se sont avérées sensibles à la position initiale du contour et au bruit de l’image. Ensuite, elles ont été améliorées afin d’utiliser les informations venant des surfaces des objets à détecter dans l’image (Mumford et al. (1989), Chan et al. (2001)). Deux grandes familles de méthodes level-set découlent de ces évolutions :
– Modèles de contours : ils utilisent les gradients d’intensité des contours de l’image pour guider la déformation des contours (Caselles et al. (1997), Kimmel et al. (1995), Malladi et al. (1995)). Elles sont sensibles au bruit et nécessite de fort gradient de niveau de gris aux interfaces.
– Modèles de régions : ils cherchent des régions homogènes pour guider la déformation des contours (Ronfard (1994), Vese et al. (2002)). Elles sont sensibles aux inhomogénéités de l’image.
De manière générale, les méthodes de segmentation par level-set, itératives par natures, sont gourmandes en ressources de calcul.
La reconstruction sur-résolue d’une image à faible résolution consiste à créer une image à une résolution plus élevée à partir d’une ou plusieurs images à faible résolution (Ziwei et al. (2014)). En règle générale, l’image sur-résolue obtenue est directement utilisée à d’autres fins (imagerie satellite par exemple) qu’une simple segmentation comme nous allons le faire ici. Le développement de ces techniques a débuté avec Harris (1964) et Goodman (1968) avec l’utilisation d’une seule image. Elles ont été améliorées par Tsai et al. (1984) grâce à l’utilisation de séquences d’images d’une même scène décalées spatialement. Le début des années 2000 voit le développement de techniques de sur-résolution utilisant des méthodes d’apprentissages (Freeman (2000), Chang et al. (2004)) comme les chaines de Markov. Ces dernières sont utilisées dans des domaines plus spécifiques (reconnaissance faciale) où elles peuvent bénéficier d’une banque de données pour l’apprentissage.
A partir de cette brève littérature, les méthodes choisies pour la comparaison sub-pixel sont les suivantes :
– La méthode développée au CORIA (Blaisot et al. (2005), Blaisot (2012), Fdida et al. (2009)).
– Une méthode level-set de Li et al. (2010) qui est peu sensible au choix du contour initial et aux inhomogénéités de niveaux de gris présentes sur l’image. Cette méthode converge rapidement (pour une level-set) et est précise jusqu’au quart de pixel avec un bon jeu de paramètres.
– Une méthode de sur-résolution bi-cubique. Elle est utilisée comme référence (Timofte et al. (2014), Zhang et al. (2016)) pour les comparaisons des techniques de sur-résolution et présente les avantages d’être simple, très rapide et déjà implémentée dans la plupart des logiciels de traitement d’images (ImageJ, Gimp, Photoshop).
– Une méthode de sur-résolution de Timofte et al. (2014) utilisant une méthode d’apprentissage. C’est une méthode rapide (pour une méthode d’apprentissage) et présentant le plus fort PSNR (ratio signal maximal sur bruit) des méthodes de ce type.
|
Table des matières
1. Introduction
2. Description multi-échelles
2.1. Introduction
2.2. Distributions de diamètres et distributions d’échelles
2.2.1. Distribution de diamètres
2.2.2. Distribution d’échelles
2.3. Applications de référence
2.3.1. Ensembles de sphères
2.3.2. Ensembles de cylindres
2.4. Application : perle sur une ficelle
2.4.1. Sphère et cylindre sans raccordement
2.4.2. Sphère et cylindre avec raccordement
2.5. Ensemble de cylindres s’amincissants
2.6. Conclusion
3. Traitement d’images et analyse sub-pixel
3.1. Introduction
3.2. Traitement d’images
3.2.1. Techniques de seuillages
3.2.2. Normalisation des images
3.2.3. Localisation des objets liquides
3.2.4. Segmentation locale des objets de l’image
3.3. Approches sub-pixel
3.3.1. Calcul du contour sub-pixel (CORIA)
3.3.2. Sub-pixel : level-set
3.3.3. Sur-résolution : méthode bi-cubique
3.3.4. Sur-résolution : méthode A+
3.3.5. Comparatif des méthodes
3.4. Mesure de la distribution d’échelle 3D
3.4.1. Détermination du squelette d’un objet
3.4.2. Mesure du volume et de la surface d’un objet à partir de son squelette
3.4.3. Mesure de la distribution d’échelle à partir des informations du squelette
3.5. Validation du calcul multi-échelles via la méthode de Monte-Carlo
3.5.1. Cas synthétiques
3.5.2. Influence de la densité de points sur les dérivées successives de e3(d)
3.5.3. Cas réel axisymétrique
3.6. Analyse de structures ligamentaires issues d’une nappe liquide turbulente
3.6.1. Dispositif expérimental
3.6.2. Résultats
3.7. Conclusion
4. Atomisation de jets libres viscoélastiques
4.1. Introduction
4.2. Dispositif expérimental
4.2.1. Système d’injection
4.2.2. Liquides
4.2.3. Points de fonctionnement
4.2.4. Système d’imagerie
4.3. Mesures préliminaires
4.3.1. Diamètre et vitesse du jet
4.3.2. Longueurs d’ondes de perturbation du jet
4.3.3. Longueurs de rupture du jet
4.4. Mesure des distributions d’échelles 3D
4.4.1. Protocole de mesure
4.4.2. Influence de la hauteur de fenêtre d’analyse sur la distribution d’échelles
4.4.3. Influence du nombre d’images sur la distribution d’échelles
4.4.4. Volume moyen du jet dans la fenêtre d’analyse
4.5. Analyse multi-échelle
4.5.1. Surface spécifique
4.5.2. Mesure des échelles caractéristiques d1 et d4
4.5.3. Identification des régimes ligamentaires
4.6. Résultats
4.6.1. Temps de relaxation
4.6.2. Taux de déformation du régime élasto-capillaire
4.6.3. Viscosité élongationelle terminale
4.6.4. Estimation de la longueur de ligament
5. Conclusion
Bibliographie